Open Source
Latest AI signals in this category
Open Sourcemodels
llama.cpp b10175 Release Expands Platform Support
The latest b10175 release of llama.cpp continues its trend of broadening platform compatibility, making it a versatile tool for developers across different systems. Notably, this update includes support for ROCm 7.2 on Ubuntu x64, which is significant for AMD GPU users seeking alternatives to NVIDIA's CUDA. The release also maintains a wide array of builds for Windows, macOS, and Linux, ensuring that developers can leverage llama.cpp's capabilities regardless of their hardware setup. While there are no groundbreaking new features, the consistent expansion of platform support solidifies llama.cpp's position as a flexible inference runtime option.
llama.cpp Releases
Open Sourcemodels
llama.cpp b10176 Release Expands Platform Support
The b10176 release of llama.cpp enhances its platform reach, notably adding ROCm 7.2 support on Ubuntu x64, which is a significant boost for AMD GPU users. This update continues to cater to a wide array of systems, from macOS to Windows and Linux, ensuring developers can deploy llama.cpp across various hardware setups. While there are no groundbreaking new features, the release solidifies llama.cpp's role as a flexible tool for AI inference. By improving compatibility and functionality, this update makes llama.cpp more accessible and practical for developers working with different systems.
llama.cpp Releases
Open Sourcemodels
llama.cpp b10158 Release Expands Platform Support
The latest b10158 release of llama.cpp continues its trend of broadening platform compatibility, though without major new features. Notably, the release includes support for ROCm 7.2 on Ubuntu x64, which is significant for AMD GPU users seeking alternatives to NVIDIA's CUDA. While KleidiAI support for Apple Silicon remains disabled, the release still covers a wide array of platforms, including Windows and openEuler. This update demonstrates llama.cpp's commitment to being a versatile inference runtime across diverse hardware configurations.
llama.cpp Releases
Open Sourcemodels
llama.cpp b10159 release enhances Metal backend
The latest b10159 release of llama.cpp introduces a new FWHT kernel for the Metal backend, significantly boosting performance for Apple Silicon users. This update, co-authored by YiChen Lv and Georgi Gerganov, also resolves a narrowing issue and refines formatting and style. Although the KleidiAI feature for macOS Apple Silicon is still disabled, the release maintains compatibility with platforms like Ubuntu, Windows, and openEuler. With ROCm 7.2 and CUDA 12 and 13 support, llama.cpp continues to evolve as a robust inference runtime, catering to diverse hardware configurations.
llama.cpp Releases
Open Sourcemodels
llama.cpp b10165 Release Adds Vulkan Support
The b10165 release of llama.cpp marks the return of Vulkan support for iq4_nl, addressing earlier concerns about shared memory allocation. This update also introduces q1_0 support for non-coopmat2 configurations, enhancing its functionality. The release continues to cater to a wide range of systems, including macOS, Linux, Windows, and openEuler, with dedicated builds for Vulkan, ROCm, and CUDA environments. While no new model architectures are introduced, this update strengthens llama.cpp's role as a flexible inference runtime across different hardware setups. The inclusion of ROCm 7.2 and CUDA 12 and 13 DLLs ensures that users on AMD and NVIDIA platforms can leverage the latest advancements without compatibility issues. This release is a testament to llama.cpp's commitment to providing robust support for diverse computing environments.
llama.cpp Releases
Open Sourcemodels
llama.cpp b10173 Release Expands Platform Support
The latest b10173 release of llama.cpp continues its trend of broadening platform compatibility, making it a versatile choice for developers across different systems. Notably, this update includes support for Vulkan on Ubuntu and Windows, as well as ROCm 7.2 on Ubuntu, which enhances GPU utilization options. While the release doesn't introduce new model architectures, it solidifies llama.cpp's position as a flexible inference runtime by catering to a wide array of hardware configurations. This means developers can now leverage llama.cpp more effectively across various hardware setups, from Apple Silicon to Windows with CUDA support.
llama.cpp Releases
Open Sourcemodels
llama.cpp b10141 Release Expands Platform Support
The latest b10141 release of llama.cpp continues its trend of broadening platform compatibility, though without major new features. Notably, it includes support for ROCm 7.2 on Ubuntu x64, which is significant for AMD GPU users seeking alternatives to NVIDIA's CUDA. The release also maintains a wide array of builds across macOS, Windows, and Linux, ensuring that developers have the flexibility to deploy on various hardware configurations. While the update doesn't introduce groundbreaking changes, it solidifies llama.cpp's position as a versatile tool for AI inference across diverse systems.
llama.cpp Releases
Open Sourcemodels
llama.cpp b10103 Release Expands Platform Support
The latest b10103 release of llama.cpp continues its trend of broadening platform compatibility, notably adding support for ROCm 7.2 on Ubuntu x64. This update ensures that AMD GPU users can leverage llama.cpp more effectively, reducing the performance gap with NVIDIA's CUDA. The release also includes Vulkan support for Ubuntu and Windows, enhancing the versatility of the software. While no new model architectures are introduced, the focus on expanding hardware compatibility makes llama.cpp increasingly accessible to a wider range of developers.
llama.cpp Releases
Open Sourcemodels
llama.cpp b10106 Release Expands Platform Support
The latest b10106 release of llama.cpp continues its trend of broadening platform compatibility, making it a versatile tool for developers across various systems. Notably, this update includes support for ROCm 7.2 on Ubuntu x64, which is significant for AMD GPU users seeking alternatives to NVIDIA's CUDA. The release also maintains its comprehensive support for Windows, macOS, and Linux, ensuring developers can leverage llama.cpp's capabilities regardless of their hardware. While no groundbreaking features are introduced, the consistent expansion of platform support solidifies llama.cpp's position as a flexible inference runtime.
llama.cpp Releases
Open Sourcemodels
Llama.cpp b10107 Release Expands Platform Support
The latest b10107 release of llama.cpp continues its trend of broadening platform compatibility, now including Vulkan support for both Ubuntu and Windows, as well as ROCm 7.2 for Ubuntu. This update signifies a step forward in making llama.cpp more accessible across diverse hardware configurations, particularly for AMD GPU users who benefit from ROCm support. While KleidiAI support on macOS Apple Silicon is disabled, the release still marks a significant expansion in the tool's versatility. This positions llama.cpp as a more inclusive inference runtime, catering to a wider range of developers and systems.
llama.cpp Releases
Open Sourcemodels
llama.cpp b10084 Release Expands Platform Support
The latest b10084 release of llama.cpp continues its trend of broadening platform compatibility, making it a versatile tool for developers across various systems. Notably, this update includes support for Ubuntu with ROCm 7.2, enhancing performance for AMD GPU users, and expands Vulkan support across multiple operating systems. While KleidiAI support for macOS Apple Silicon is disabled, the release still offers a comprehensive range of builds for Windows, Linux, and openEuler. This update solidifies llama.cpp's position as a go-to runtime for diverse hardware configurations, though it doesn't introduce new model architectures.
llama.cpp Releases
Open Sourcemodels
llama.cpp b10087 Release Expands Platform Support
The b10087 release of llama.cpp marks a significant step in broadening its hardware compatibility, with ROCm 7.2 now available for Ubuntu x64, offering AMD GPU users a more competitive alternative to NVIDIA's CUDA. This update also introduces Vulkan support, enhancing the software's adaptability across different operating systems. While the release doesn't bring new model architectures, the focus remains on making llama.cpp a versatile tool for developers. By expanding support for various hardware configurations, llama.cpp continues to position itself as a go-to solution for diverse development environments.
llama.cpp Releases
Open Sourcemodels
llama.cpp b10088 Release Expands Platform Support
The b10088 release of llama.cpp marks another step in broadening its platform compatibility, making it a valuable tool for developers working across different systems. This update introduces support for Ubuntu with ROCm 7.2, which is particularly beneficial for those using AMD GPUs, offering enhanced performance. The release continues to support a wide array of platforms, including Windows, macOS, and Linux, ensuring developers can utilize llama.cpp's capabilities on their preferred systems. While there are no groundbreaking new features, the ongoing expansion of platform support strengthens llama.cpp's role as a flexible inference runtime for various computing environments.
llama.cpp Releases
Open Sourcemodels
llama.cpp b10059 Release Expands Platform Support
The b10059 release of llama.cpp enhances its platform compatibility, now supporting numerous operating systems and architectures. A key change is the defaulting of Hadamard multiplication to a CPU routine, which may lead to more consistent performance across setups. Although KleidiAI support for Apple Silicon is currently disabled, the release still accommodates platforms like macOS, Windows, and Linux, with configurations such as Vulkan and ROCm 7.2. While no new models are introduced, this update solidifies llama.cpp's role as a flexible inference runtime across diverse hardware environments.
llama.cpp Releases
 © Hugging Face Blog
© Hugging Face BlogOpen Sourceagents
Grabette: Open System for Robot Data Collection
Grabette is a new open-source system designed to simplify the collection of robot manipulation data. By using a handheld gripper equipped with cameras, it allows users to record tasks without needing a robot or lab setup. This democratizes data collection, enabling anyone to contribute to a large, collaborative dataset. The system is built on standard, easily accessible components, making it accessible for widespread use. This release aims to address the data bottleneck in robot learning by encouraging community participation in building diverse datasets.
Hugging Face Blog
Open Sourcemodels
llama.cpp b10056 Release Expands Platform Support
The b10056 release of llama.cpp continues its trend of broadening platform compatibility, making it a versatile tool for developers across various systems. Notably, this update includes support for Ubuntu with ROCm 7.2, enhancing performance for AMD GPU users. The release also maintains its commitment to diverse hardware by supporting both Intel and Apple Silicon on macOS, as well as Vulkan and OpenVINO on Windows. While no groundbreaking new features are introduced, the steady expansion of supported environments ensures that llama.cpp remains a go-to choice for developers seeking flexibility in AI model deployment.
llama.cpp Releases
Open Sourcecoding
llama.cpp b10058 release enhances Vulkan support
The b10058 release of llama.cpp marks a notable step forward with the addition of Vulkan Q2_0, significantly boosting performance for matrix-vector multiplication tasks. By optimizing the rows per workgroup, the update addresses initial inefficiencies, leading to improved computational efficiency. The release also tackles merge conflicts and fine-tunes error thresholds for specific operations. While it doesn't introduce new model architectures, this update strengthens llama.cpp's role as a robust tool for developers across platforms like macOS, Linux, Windows, and openEuler. The inclusion of ROCm 7.2 and CUDA 12 and 13 builds further broadens its applicability, making it a more versatile choice for diverse development environments.
llama.cpp Releases
Open Sourcemodels
llama.cpp b10066 Release Expands Platform Support
The b10066 release of llama.cpp marks another step in broadening its compatibility across different hardware environments. With the addition of ROCm 7.2 support on Ubuntu x64, AMD GPU users can now enjoy improved performance, narrowing the gap with NVIDIA's CUDA. This update continues to cater to a wide range of systems, including macOS, Windows, and Linux, ensuring developers can utilize llama.cpp's capabilities regardless of their setup. Although there are no new groundbreaking features, the ongoing expansion of platform support reinforces llama.cpp's reputation as a flexible and adaptable tool for AI inference.
llama.cpp Releases
Open Sourcemodels
llama.cpp b10045 Release Expands Platform Support
The b10045 release of llama.cpp focuses on broadening its platform compatibility, though it doesn't introduce major new features. This update notably includes Vulkan support for Ubuntu and Windows, alongside ROCm 7.2 for Ubuntu, enhancing GPU utilization options for developers. While KleidiAI support for macOS Apple Silicon remains disabled, the release still covers a wide array of operating systems and architectures, offering developers increased flexibility in deployment. This update solidifies llama.cpp's position as a versatile inference runtime across multiple systems, rather than delivering groundbreaking changes.
llama.cpp Releases
Open Sourcemodels
llama.cpp b10046 Release Expands Platform Support
The b10046 release of llama.cpp continues to broaden its platform compatibility, making it an adaptable tool for developers working across different systems. This update notably includes support for Ubuntu with ROCm 7.2, which enhances performance for AMD GPU users. Windows users gain from the inclusion of CUDA 12 and 13 DLLs, ensuring they can leverage the latest NVIDIA technologies. While macOS Apple Silicon support remains strong, the KleidiAI feature is temporarily disabled. This release reflects llama.cpp's ongoing effort to be a comprehensive inference runtime across a wide range of hardware configurations.
llama.cpp Releases
Open Sourcemodels
llama.cpp b10047 Release Expands Platform Support
The b10047 release of llama.cpp marks another step in its mission to support diverse hardware environments, now extending compatibility to platforms like macOS, Linux, and Windows. This update brings Vulkan support to Ubuntu and Windows, enhancing their graphics processing capabilities. The addition of ROCm 7.2 for Ubuntu x64 is a significant move for AMD GPU users, offering improved performance. While the release doesn't feature new models, it continues to support CUDA for NVIDIA users, ensuring robust performance across different setups. This version focuses on making llama.cpp a more versatile tool for developers working with various hardware configurations.
llama.cpp Releases
Open Sourcemodels
llama.cpp b10048 Release Expands Platform Support
The b10048 release of llama.cpp continues its trend of broadening platform compatibility, notably adding support for ROCm 7.2 on Ubuntu x64, which enhances performance for AMD GPU users. This update also includes Vulkan support across multiple operating systems, providing more flexibility for developers working with graphics-intensive applications. While the release doesn't introduce new model architectures, it solidifies llama.cpp's position as a versatile inference runtime across diverse hardware configurations. Developers can now leverage these enhancements to optimize AI workloads on a wider array of systems.
llama.cpp Releases
Open Sourcemodels
llama.cpp b10050 Release Expands Platform Support
The b10050 release of llama.cpp marks a significant step in broadening its reach across various hardware platforms. This update introduces Vulkan support for both Ubuntu and Windows, and adds ROCm 7.2 support on Ubuntu, which is a boon for AMD GPU users seeking more options. The release also continues to support CUDA 12 and 13 on Windows, ensuring that NVIDIA users can take advantage of the latest developments. Although no new model architectures are included, this update reinforces llama.cpp's role as a flexible inference runtime for a wide range of systems, making it more adaptable for developers working with different hardware configurations.
llama.cpp Releases
Open Sourcemodels
llama.cpp b10054 Release Expands Platform Support
The b10054 release of llama.cpp significantly broadens its reach by adding support for a diverse range of systems, including macOS, Linux, Windows, and openEuler. This update is particularly beneficial for AMD GPU users with the inclusion of ROCm 7.2 support on Ubuntu, enhancing computational performance. Vulkan support is now available, offering improved graphics processing capabilities. Although the KleidiAI feature is disabled for macOS, the release still marks a substantial step in making llama.cpp a more adaptable tool for developers. While no new models are introduced, the focus remains on extending the usability and accessibility of existing features.
llama.cpp Releases
Open Sourcecoding
llama.cpp b10003 release enhances tokenization
The b10003 release of llama.cpp brings a notable improvement to its tokenization tool by adopting a unified approach to argument parsing. This update replaces the previous custom implementations, enhancing the handling of Windows UTF-8 and file reading. By exposing model-sourcing flags to the LLAMA_EXAMPLE_TOKENIZE tool, developers gain more flexibility. The release ensures backward compatibility by defaulting parse_special to true and improves error handling with LOG_ERR. These changes aim to provide a more streamlined and efficient tokenization process, making it easier for developers to utilize the tool on various systems.
llama.cpp Releases
Open Sourcecoding
llama.cpp b10005 Release Enhances Compatibility
The b10005 release of llama.cpp focuses on improving its functionality and compatibility across a broad spectrum of systems. This update addresses issues in DeepseekV4 by fixing sequence removal and implementing a proper sequence copy function. It extends support to macOS, Linux, Windows, and openEuler, with specific builds for technologies like Vulkan, ROCm, and CUDA. Notably, the release includes ROCm 7.2 for Ubuntu x64 and CUDA 12 and 13 for Windows x64, ensuring better performance on these platforms. While it doesn't introduce groundbreaking features, this release strengthens llama.cpp's role as a reliable tool for developers working in diverse computing environments.
llama.cpp Releases
Open Sourcemodels
llama.cpp b10012 release expands platform support
The latest b10012 release of llama.cpp continues its trend of broadening platform compatibility, now including support for a variety of systems across macOS, Linux, Windows, and openEuler. Notably, this update introduces Vulkan support on Ubuntu and Windows, and adds ROCm 7.2 for Ubuntu x64, enhancing GPU utilization options. While KleidiAI support is disabled for macOS, the release still offers a comprehensive range of builds, including CUDA 12 and 13 for Windows. This update solidifies llama.cpp's position as a versatile inference runtime, catering to a wide array of hardware configurations.
llama.cpp Releases
Open Sourcemodels
llama.cpp b10015 Release Expands Platform Support
The b10015 release of llama.cpp marks another step in its evolution, enhancing its utility for developers working with diverse systems. With ROCm 7.2 now supported on Ubuntu, AMD GPU users gain a viable alternative to NVIDIA's CUDA, broadening their options for local inference. The update also brings Vulkan support to both Windows and Ubuntu, underscoring the project's commitment to flexible and efficient inference solutions. While the release doesn't introduce new model architectures, it strengthens llama.cpp's reputation as a versatile runtime for a wide range of hardware configurations.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9973 Release Expands Platform Support
The b9973 release of llama.cpp focuses on enhancing compatibility across a wide array of systems, though it doesn't introduce major new features. This update is particularly notable for adding ROCm 7.2 support on Ubuntu x64, offering AMD GPU users a viable alternative to NVIDIA's CUDA. The release continues to provide extensive builds for macOS, Linux, Windows, and openEuler, ensuring that developers can deploy llama.cpp in varied environments. While the update lacks groundbreaking innovations, it strengthens llama.cpp's role as a versatile tool for AI inference, accommodating diverse hardware configurations.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9975 Release Expands Platform Support
The b9975 release of llama.cpp continues its focus on enhancing platform compatibility, though it doesn't introduce major new features. This update includes ROCm 7.2 support for Ubuntu x64, which is a significant development for AMD GPU users looking for alternatives to NVIDIA's CUDA. Although KleidiAI support for macOS Apple Silicon is currently disabled, the release still supports numerous operating systems, including Windows and openEuler. By covering diverse hardware configurations, llama.cpp strengthens its role as a flexible inference runtime, even without new model architectures.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9978 Release Expands Platform Support
The b9978 release of llama.cpp continues to broaden its platform reach, making it a versatile tool for developers across various systems. This update notably includes support for Ubuntu with ROCm 7.2, which enhances compatibility for AMD GPU users. The release also maintains its commitment to supporting a wide array of systems with builds for Windows, macOS, and openEuler, although some configurations like KleidiAI on Apple Silicon are not enabled. With this update, llama.cpp solidifies its role as a flexible runtime for developers working across different hardware and operating systems.
llama.cpp Releases
Open Sourcecoding
Llama.cpp b9979 Release Fixes Prompt Truncation
The latest b9979 release of llama.cpp addresses a critical issue with silent prompt truncation caused by embedded NUL bytes. This fix ensures that prompts are no longer cut off unexpectedly, preserving the integrity of message content during tokenization. The update also includes various platform-specific builds, enhancing compatibility across macOS, Linux, Windows, and openEuler systems. While the release doesn't introduce new features, it solidifies the reliability of llama.cpp for developers working with diverse hardware configurations.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9947 Release Expands Platform Support
The latest b9947 release of llama.cpp continues its trend of broadening platform compatibility, though without major new features. Notably, the release includes support for ROCm 7.2 on Ubuntu x64, which is significant for AMD GPU users seeking alternatives to NVIDIA's CUDA. While KleidiAI support for Apple Silicon remains disabled, the release still covers a wide array of systems, from Windows CUDA 13 to Ubuntu Vulkan. This update solidifies llama.cpp's role as a versatile inference runtime, though it doesn't introduce groundbreaking changes.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9949 Release Expands Platform Support
The latest b9949 release of llama.cpp continues its trend of broadening platform compatibility, notably adding support for ROCm 7.2 on Ubuntu x64, which is a significant step for AMD GPU users. This release also includes updates for Windows with CUDA 12 and 13, enhancing its utility for developers working across different hardware configurations. While KleidiAI support for macOS Apple Silicon is disabled, the release still marks a steady expansion of llama.cpp's reach across diverse systems. This update doesn't introduce new models but strengthens the framework's versatility and accessibility for developers.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9950 release focuses on platform fixes
The b9950 release of llama.cpp is a technical update that addresses specific platform issues and enhances code reliability with new unit tests for llama-batch. It resolves build problems on Win32 and introduces assertions for methods that are not yet implemented. While this update doesn't bring new models or groundbreaking features, it ensures compatibility across a wide array of systems, including macOS, Linux, Windows, and openEuler. This release is a step towards refining the software's robustness and usability across different hardware configurations, making it more stable and reliable for developers.
llama.cpp Releases
Open Sourcecoding
llama.cpp b9957 Release Enhances Tools and Builds
The b9957 release of llama.cpp brings notable improvements to its server tools and build processes, enhancing the development experience. With the introduction of a new tools_io abstraction and improvements to the edit tool, developers can expect more streamlined workflows. The update also addresses build issues and reorganizes utilities into class members, indicating a move towards a more structured codebase. While it doesn't introduce groundbreaking features, the inclusion of ROCm 7.2 and support for CUDA 12 and 13 DLLs highlights a focus on compatibility and performance. These enhancements make llama.cpp a more stable and reliable option for developers working on Apple Silicon, Windows, and Linux systems.
llama.cpp Releases
 © TechCrunch AI
© TechCrunch AIOpen Sourceresearch
Hugging Face CEO Advocates for Open Source AI
Clem Delangue, CEO of Hugging Face, underscores the critical role of open source AI, comparing the platform to a GitHub for AI models and datasets. He observes that as companies expand, they often move from expensive proprietary APIs to more affordable open source options, which he believes is essential for democratizing AI technology. Delangue voices concerns about the risk of a few large companies dominating the AI landscape, advocating for openness and transparency, particularly in the field of robotics. This approach is reflected in Hugging Face's decision to focus on capital efficiency rather than traditional fundraising, even declining a significant investment offer from Nvidia to stay true to its open source principles.
TechCrunch AI
Open Sourcemodels
llama.cpp b9930 Release Expands Platform Support
The b9930 release of llama.cpp marks another step in broadening its platform reach, now covering macOS, Linux, Windows, and openEuler. This update includes Ubuntu builds with ROCm 7.2, which boosts performance for AMD GPU users, and Windows builds with CUDA 12 and 13, catering to NVIDIA users. While no new models are introduced, the focus is on enhancing compatibility across various hardware setups. By supporting both CPU and GPU environments, llama.cpp is positioning itself as a versatile inference runtime for a wide range of users.
llama.cpp Releases
Open Sourcemodels
Llama.cpp b9932 Release Enhances Performance
The b9932 release of llama.cpp is all about boosting performance, particularly by turning off the FA mask_opt on GCN for Vulkan, which should lead to better efficiency. It also brings back mask optimization for attention head sizes over 256, showing a clear focus on computational refinement. While no new models are introduced, the update broadens compatibility with macOS, Linux, Windows, and openEuler, offering specific builds for Vulkan, ROCm, and CUDA. This release is a significant step in making llama.cpp more adaptable and efficient across different hardware setups, ensuring it meets the needs of diverse computing environments.
llama.cpp Releases
 © Hugging Face Blog
© Hugging Face BlogOpen Sourceagents
NVIDIA's Nemotron Enhances AI with Open Synthetic Data
NVIDIA's Nemotron initiative is making strides in AI development by leveraging open synthetic data to enhance agent behavior and reproducibility. By releasing over 10 trillion pre-training tokens and millions of post-training samples, NVIDIA aims to make AI agents more adaptable and inspectable. The Nemotron Post-Training v3 Prompt Atlas offers an interactive way to explore this data, helping developers understand and refine model behaviors. This approach not only preserves proprietary data but also fosters a collaborative AI ecosystem, allowing diverse contributors to improve AI systems without compromising sensitive information.
Hugging Face Blog
Open Sourcecoding
Llama.cpp b9874 Release Enhances CUDA Support
The b9874 release of llama.cpp introduces a CUDA implementation specifically for quantized types, significantly boosting performance for developers using NVIDIA GPUs. This update is a testament to the project's collaborative nature, incorporating community-driven code optimizations. While no new model architectures are introduced, the release enhances llama.cpp's functionality across platforms like macOS, Linux, and Windows. With ROCm 7.2 support on Ubuntu and KleidiAI integration on Apple Silicon, the update broadens the tool's applicability. This positions llama.cpp as an increasingly versatile option for developers focused on efficient AI model deployment.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9877 Release Expands Platform Support
The b9877 release of llama.cpp focuses on expanding its platform compatibility, though it doesn't introduce major new features. This update includes ROCm 7.2 support for Ubuntu x64, providing AMD GPU users with a viable alternative to NVIDIA's CUDA. While KleidiAI support for macOS Apple Silicon is currently disabled, the release still spans a wide range of platforms, including Windows and openEuler. By covering such diverse hardware environments, llama.cpp continues to position itself as a versatile inference runtime.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9861 Release Expands Platform Support
The b9861 release of llama.cpp significantly broadens its reach by adding support for multiple platforms, enhancing its utility for developers. This update includes Ubuntu builds with ROCm 7.2, which is a boon for AMD GPU users seeking better performance. Windows users benefit from the inclusion of CUDA 12 and 13 builds, catering to those with NVIDIA hardware. Although the KleidiAI feature for macOS Apple Silicon is currently disabled, the release still marks a substantial step forward in making llama.cpp a versatile tool across different environments. This update reinforces llama.cpp's role as a comprehensive inference runtime, accommodating a wide range of hardware configurations.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9867 Release Expands Platform Support
The b9867 release of llama.cpp quietly enhances its versatility by expanding platform compatibility. With the addition of spec-draft-p-min in DFlash, the update brings new functionality to the table. Developers can now leverage a variety of builds across macOS, Linux, Windows, and openEuler, with specific configurations for Vulkan, ROCm, and CUDA. While the release doesn't feature new models, it solidifies llama.cpp's role as a flexible inference runtime, accommodating diverse hardware setups and making it a more robust tool for developers.
llama.cpp Releases
Open Sourcecoding
Llama.cpp b9849 Release Enhances IPv6 Handling
The latest b9849 release of llama.cpp introduces improved handling of bracketed IPv6 literals in URL authorities, aligning with RFC 3986 standards. This update ensures that IPv6 hosts are correctly formatted in various logs and headers, enhancing network communication reliability. Additionally, the release maintains explicit rejection of unsupported schemes in the URL parser, ensuring robust error handling. While there are no groundbreaking new features, this update solidifies llama.cpp's position as a reliable tool for developers working with diverse network configurations.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9852 release expands OpenCL support
The latest b9852 release of llama.cpp marks a significant step in broadening hardware compatibility with the introduction of initial OpenCL support for q1_0, including Adreno GEMM/GEMV enhancements. This update is particularly noteworthy for developers working on diverse platforms, as it extends support across macOS, Linux, Windows, and Android, with specific improvements for Apple Silicon and Vulkan on Ubuntu. While the release doesn't introduce new models, it strengthens llama.cpp's position as a versatile inference runtime, making it more accessible to a wider range of hardware configurations. This expansion means developers can now leverage llama.cpp's capabilities on more devices, enhancing its utility in varied environments.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9855 Release Expands Platform Support
The latest b9855 release of llama.cpp continues its trend of broadening platform compatibility, notably adding support for ROCm 7.2 on Ubuntu x64. This update ensures that AMD GPU users can leverage llama.cpp more effectively, narrowing the gap with NVIDIA's CUDA. The release also maintains a wide array of builds across macOS, Linux, Windows, and openEuler, though some configurations like KleidiAI on Apple Silicon remain disabled. This iteration doesn't introduce new model architectures but solidifies llama.cpp's position as a versatile inference runtime across diverse hardware setups.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9856 Release Expands Platform Support
The latest b9856 release of llama.cpp continues its trend of broadening platform compatibility, though without major new features. Notably, the release includes support for ROCm 7.2 on Ubuntu x64, which is significant for AMD GPU users seeking alternatives to NVIDIA's CUDA. While the KleidiAI feature for Apple Silicon remains disabled, the release still covers a wide array of platforms, including Windows, Linux, and Android. This update reinforces llama.cpp's position as a versatile inference runtime, though it doesn't introduce groundbreaking changes.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9831 release adds DFlash support
The b9831 release of llama.cpp marks a significant enhancement with the addition of DFlash, which brings sliding window attention per layer types. This update is particularly beneficial for developers on macOS, Linux, and Windows, as it extends the tool's compatibility and functionality across these platforms. With ROCm 7.2 now available on Ubuntu, AMD GPU users gain a more robust option for local inference. While no new models are introduced, this release solidifies llama.cpp's role as a versatile inference runtime, especially for those not reliant on NVIDIA hardware. The update also includes various platform-specific improvements, making it a comprehensive upgrade for developers.
llama.cpp Releases
Open Sourcecoding
llama.cpp b9832 Release Adds Debugging Feature
The b9832 release of llama.cpp introduces a new debugging capability with the --dump-prog option in jinja, co-authored by Sigbjørn Skjæret. This enhancement is designed to streamline the debugging process for developers. The update also extends compatibility across various systems, including macOS, Linux, Windows, and openEuler, ensuring developers can work seamlessly in their preferred environments. While the release doesn't bring new models or quantization techniques, it reinforces llama.cpp's role as a flexible tool for developers. With ROCm 7.2 and CUDA 12 and 13 support, the platform continues to cater to a broad spectrum of hardware configurations. This update is a testament to llama.cpp's commitment to improving developer experience.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9838 Release Expands Platform Support
The latest b9838 release of llama.cpp continues its trend of broadening platform compatibility, though without any groundbreaking new features. Notably, the release includes support for ROCm 7.2 on Ubuntu x64, which is significant for AMD GPU users seeking alternatives to NVIDIA's CUDA. The update also maintains a wide array of builds across macOS, Linux, Windows, and openEuler, ensuring that developers on diverse systems can leverage llama.cpp's capabilities. While the release doesn't introduce new models or quantization methods, it solidifies llama.cpp's position as a versatile inference runtime across multiple architectures.
llama.cpp Releases
Open Sourcemodels
Llama.cpp b9842 Release Expands Platform Support
The latest b9842 release of llama.cpp continues its trend of broadening platform compatibility, making it a versatile tool for developers across various systems. Notably, this update includes support for ROCm 7.2 on Ubuntu, which is significant for AMD GPU users seeking alternatives to NVIDIA's CUDA. The release also maintains its comprehensive support for Windows, macOS, and Linux, ensuring that developers can leverage llama.cpp's capabilities regardless of their hardware setup. While no new model architectures are introduced, the focus on platform expansion solidifies llama.cpp's role as a flexible inference runtime.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9843 Release Expands Platform Support
The latest b9843 release of llama.cpp continues its trend of broadening platform compatibility, now including support for a variety of systems such as Ubuntu with Vulkan and ROCm 7.2, as well as Windows with CUDA 12 and 13. This update reflects a commitment to making llama.cpp a versatile tool for developers across different hardware and operating systems. While there are no groundbreaking new features, the expanded support ensures that more developers can leverage llama.cpp's capabilities without being limited by their platform choice. This release is a step towards making llama.cpp a more universally accessible inference runtime.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9821 Release Expands Platform Support
The latest b9821 release of llama.cpp enhances user interaction with new command-line options like --version, --licenses, and --help. This update significantly broadens platform compatibility, adding support for Vulkan and ROCm 7.2 on Ubuntu, and CUDA 12 and 13 on Windows. Although KleidiAI support is currently disabled for macOS Apple Silicon, the release still caters to numerous operating systems and architectures. This update underscores llama.cpp's commitment to making its tools more accessible and functional for developers across different computing environments.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9822 Release Expands Platform Support
The b9822 release of llama.cpp focuses on enhancing platform compatibility, though it doesn't introduce groundbreaking features. This update includes support for Ubuntu x64 with ROCm 7.2, providing a valuable option for AMD GPU users who prefer alternatives to NVIDIA's CUDA. The release also maintains extensive support across macOS, Windows, and Linux, allowing developers to deploy llama.cpp on a wide range of systems. While there are no new models or quantization methods, this release strengthens llama.cpp's role as a flexible inference runtime for developers working with various hardware configurations.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9823 Release Expands Platform Support
The latest b9823 release of llama.cpp continues its trend of broadening platform compatibility, though without major new features. Notably, the release includes support for ROCm 7.2 on Ubuntu x64, which is significant for AMD GPU users seeking alternatives to NVIDIA's CUDA. While KleidiAI support for macOS Apple Silicon is disabled, the release still covers a wide array of platforms, from Windows CUDA 12 and 13 to various Linux and Windows configurations. This update reinforces llama.cpp's role as a versatile inference runtime, though it doesn't introduce groundbreaking changes.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9825 Release Expands Platform Support
The b9825 release of llama.cpp marks a significant expansion in platform compatibility, with ROCm 7.2 now available for Ubuntu x64, offering a boost for AMD GPU users. This update also introduces Vulkan support, enhancing performance capabilities for developers working on diverse systems. Although the KleidiAI feature is disabled on macOS Apple Silicon, the release still provides a comprehensive array of builds for operating systems like Windows and openEuler. This means developers can now choose from a wider range of hardware and software environments to run llama.cpp, making it a more adaptable tool in the AI development toolkit.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9781 Release Expands Platform Support
The latest b9781 release of llama.cpp continues its trend of broadening platform compatibility, though without major new features. Notably, the release includes support for ROCm 7.2 on Ubuntu x64, which is significant for AMD GPU users seeking alternatives to NVIDIA's CUDA. While KleidiAI support for macOS Apple Silicon is disabled, the release still covers a wide array of platforms, including Windows and openEuler. This update reinforces llama.cpp's position as a versatile inference runtime, though it remains focused on platform expansion rather than introducing new model architectures.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9782 Release Expands Platform Support
The latest b9782 release of llama.cpp continues its trend of broadening platform compatibility, though without major new features. Notably, the release includes support for ROCm 7.2 on Ubuntu x64, which is significant for AMD GPU users seeking alternatives to NVIDIA's CUDA. While KleidiAI support for Apple Silicon remains disabled, the release still covers a wide array of platforms, from Windows to openEuler. This update solidifies llama.cpp's position as a versatile inference runtime, though it doesn't introduce groundbreaking changes.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9785 Release Expands Platform Support
The latest b9785 release of llama.cpp continues its trend of broadening platform compatibility, though without major new features. Notably, the release includes support for ROCm 7.2 on Ubuntu x64, which is significant for AMD GPU users seeking alternatives to NVIDIA's CUDA. While KleidiAI support for Apple Silicon remains disabled, the release still covers a wide array of platforms, from macOS to Windows and openEuler. This update solidifies llama.cpp's position as a versatile inference runtime, though it doesn't introduce groundbreaking changes.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9786 Release Expands Platform Support
The latest b9786 release of llama.cpp continues its trend of broadening platform compatibility, though without major new features. Notably, the release includes support for ROCm 7.2 on Ubuntu x64, which is significant for AMD GPU users seeking alternatives to NVIDIA's CUDA. While KleidiAI support for Apple Silicon is disabled, the release still covers a wide array of systems, from Windows with CUDA 13.3 DLLs to Ubuntu with Vulkan support. This update is more about solidifying llama.cpp's role as a versatile inference runtime across diverse hardware rather than introducing groundbreaking new capabilities.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9787 Release Expands Platform Support
The b9787 release of llama.cpp continues its trend of broadening platform compatibility, though without major new features. Notably, it includes support for ROCm 7.2 on Ubuntu x64, which is significant for AMD GPU users seeking alternatives to NVIDIA's CUDA. The release also maintains a wide array of builds across macOS, Linux, Windows, and openEuler, ensuring that developers on diverse systems can leverage llama.cpp for AI inference. While KleidiAI support on Apple Silicon remains disabled, this release highlights llama.cpp's ongoing evolution as a versatile tool for AI developers.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9789 Release Expands Platform Support
The latest b9789 release of llama.cpp continues its trend of broadening platform compatibility, though without major new features. Notably, the release includes support for Ubuntu x64 with ROCm 7.2, enhancing AMD GPU usability, and Windows x64 with CUDA 13.3 DLLs, catering to NVIDIA users. While KleidiAI support for macOS Apple Silicon is disabled, the release still covers a wide range of systems, including Vulkan and OpenVINO support across different operating environments. This update solidifies llama.cpp's position as a versatile inference runtime, though it doesn't introduce groundbreaking changes.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9803 Release Expands Platform Support
The latest b9803 release of llama.cpp continues its trend of broadening platform compatibility, making it a versatile tool for developers across various systems. Notably, this update includes support for Vulkan on Ubuntu and Windows, as well as ROCm 7.2 on Ubuntu, which enhances GPU utilization options. The inclusion of CUDA 12 and 13 DLLs for Windows x64 further solidifies its position as a flexible inference runtime. While no new model architectures are introduced, the release reinforces llama.cpp's commitment to being a comprehensive solution for diverse hardware environments.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9771 Release Trims Shader Variants
The b9771 release of llama.cpp brings a notable optimization by setting 'mul_mm ALIGNED' as a spec constant, effectively reducing the shader variant explosion and cutting down the binary size. This change is particularly advantageous for developers using Vulkan, as it simplifies the compilation process. While the update doesn't introduce new features, it continues to enhance the platform's compatibility across macOS, Linux, Windows, and openEuler. This release is a step forward in making llama.cpp more efficient and accessible for developers working with different hardware setups, including Apple Silicon, ROCm, and CUDA environments.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9773 Release Expands Platform Support
The b9773 release of llama.cpp continues its trend of broadening platform compatibility, though without major new features. Notably, it includes support for ROCm 7.2 on Ubuntu x64, which is significant for AMD GPU users seeking alternatives to NVIDIA's CUDA. The release also maintains a wide array of builds across macOS, Linux, Windows, and openEuler, ensuring that developers can deploy llama.cpp in many different computing environments. While the update doesn't introduce groundbreaking changes, it solidifies llama.cpp's position as a versatile tool for AI inference across multiple systems.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9776 Release Expands Platform Support
The latest b9776 release of llama.cpp continues its trend of broadening platform compatibility, making it a versatile choice for developers across different systems. Notably, this update includes support for ROCm 7.2 on Ubuntu x64, which is significant for AMD GPU users seeking alternatives to NVIDIA's CUDA. The release also maintains a wide array of builds for macOS, Windows, and Linux, ensuring that developers can leverage llama.cpp's capabilities on their preferred platforms. While there are no groundbreaking new features, the consistent expansion of platform support solidifies llama.cpp's position as a flexible inference runtime.
llama.cpp Releases
 © Hugging Face Blog
© Hugging Face BlogOpen Sourcecoding
Hugging Face Automates Weekly Releases with AI
Hugging Face has streamlined its release process for the huggingface_hub Python client, moving from a 4-6 week cycle to weekly releases. This shift is powered by a combination of open-source tools and AI, which drafts release notes and automates mechanical tasks, while humans oversee critical judgment areas. The process is designed to be replicable by other maintainers, emphasizing transparency and adaptability. This change not only accelerates the release cycle but also ensures that updates are consistently delivered without the need for proprietary tools.
Hugging Face Blog
Open Sourcecoding
OpenAI Launches Patch the Planet Initiative
OpenAI's new initiative, Patch the Planet, aims to bolster the security of open-source projects by assisting maintainers in identifying and addressing vulnerabilities. This effort combines AI technology with expert reviews to ensure that open-source software remains robust and secure. By providing tools and support, OpenAI is addressing a critical need in the open-source community, where security can often be overlooked due to resource constraints. This initiative could significantly enhance the reliability of widely-used open-source software, making it safer for developers and users alike.
OpenAI
Open Sourcemodels
llama.cpp b9748 release expands platform support
The latest b9748 release of llama.cpp continues its trend of broadening platform compatibility, notably adding support for ROCm 7.2 on Ubuntu x64. This update ensures that AMD GPU users can leverage llama.cpp more effectively, narrowing the gap with NVIDIA's CUDA. The release also includes Vulkan support on several operating systems, enhancing performance options for developers. While there are no groundbreaking new features, this update solidifies llama.cpp's position as a versatile inference runtime across diverse hardware configurations.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9750 Release Expands Platform Support
The latest b9750 release of llama.cpp continues its trend of broadening platform compatibility, notably with the inclusion of ROCm 7.2 for Ubuntu x64, which enhances support for AMD GPUs. This update also refines the codebase by implementing a call statement and simplifying certain functions, which could improve performance and maintainability. While KleidiAI support for macOS Apple Silicon is disabled, the release still offers a wide array of builds across macOS, Linux, Windows, and openEuler. This iteration doesn't introduce new models but strengthens llama.cpp's position as a versatile inference runtime across diverse hardware configurations.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9751 Release Expands Platform Support
The latest b9751 release of llama.cpp continues its trend of broadening platform compatibility, though without major new features. Notably, the release includes support for ROCm 7.2 on Ubuntu x64, which is significant for AMD GPU users seeking alternatives to NVIDIA's CUDA. The update also maintains a wide array of builds across macOS, Linux, Windows, and openEuler, ensuring that developers have the flexibility to deploy on diverse systems. While the KleidiAI feature for Apple Silicon is disabled, this release highlights llama.cpp's ongoing commitment to being a versatile inference runtime across multiple environments.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9753 Release Fixes and Enhancements
The b9753 release of llama.cpp refines the server's progress reporting for loading specific models, adding a 'stages' list to improve clarity. This update focuses on enhancing existing functionalities across macOS, Linux, Windows, and openEuler, rather than introducing new features. By addressing technical details and improving compatibility, llama.cpp strengthens its role as a versatile tool for developers working with different hardware setups. These changes, while seemingly minor, contribute to a smoother and more reliable user experience, ensuring that llama.cpp remains a robust choice for AI inference across diverse environments.
llama.cpp Releases
Open Sourcecoding
llama.cpp b9724 Release with Bug Fixes
The b9724 release of llama.cpp is all about enhancing stability through a series of bug fixes, including improvements to build processes and overflow prevention in the area() function. This update ensures smoother operations across macOS, Windows, and Ubuntu, with specific support for Vulkan and ROCm 7.2 on Ubuntu. While it doesn't introduce groundbreaking features, the release strengthens llama.cpp's reliability as a tool for developers working in diverse environments. By refining and optimizing the platform, this update makes llama.cpp a more robust choice for AI development, ensuring compatibility with CUDA 12 and 13 on Windows and KleidiAI on Apple Silicon.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9728 Release Expands Platform Support
The latest b9728 release of llama.cpp continues its trend of broadening platform compatibility, though with some notable exceptions. While macOS Apple Silicon support is present, the KleidiAI feature is disabled, indicating a focus on stability over new features. The release also includes support for a variety of Linux distributions, including Ubuntu with ROCm 7.2 and Vulkan, as well as Windows with CUDA 12 and 13. This update highlights llama.cpp's commitment to being a versatile inference runtime across diverse hardware, though it remains conservative in introducing new capabilities.
llama.cpp Releases
Open Sourcemodels
Llama.cpp b9732 Release Refines Communication
The b9732 release of llama.cpp enhances the internal workings of server components, focusing on child-to-router communication. This update addresses the wakeup case and improves the update_status function, while also adding new documentation. Although it doesn't bring new model architectures, it broadens platform support, notably with ROCm 7.2 on Ubuntu x64, which benefits AMD GPU users. The release also maintains support for various configurations, including CUDA 12 and 13 on Windows x64. This iteration is about strengthening the infrastructure and ensuring smoother operations across supported systems.
llama.cpp Releases
Open Sourcecoding
llama.cpp b9684 Release Adds 3D Convolution
The b9684 release of llama.cpp marks a significant enhancement with the integration of 3D convolution, boosting its ability to handle complex data processing tasks. This update also brings optimizations and a cleaner codebase, enhancing overall efficiency. The release extends support across a broad spectrum of platforms, including macOS, Linux, and Windows, with specific configurations like Vulkan, ROCm, and SYCL. By expanding its platform compatibility and functionality, llama.cpp becomes an even more versatile tool for developers tackling diverse AI challenges.
llama.cpp Releases
Open Sourcecoding
llama.cpp b9685 Release Enhances SYCL Support
The b9685 release of llama.cpp brings notable advancements in SYCL support, particularly with the addition of device-to-device memory copy via the SYCL API. This update also refines the detection method for peer-to-peer communication, resolving previous conflicts. While there are no new model architectures introduced, the release enhances the platform's adaptability across macOS, Linux, and Windows. With ROCm 7.2 support on Ubuntu and CUDA 12 and 13 DLLs for Windows, llama.cpp becomes a more robust choice for developers working with diverse hardware configurations. The inclusion of KleidiAI on Apple Silicon further optimizes performance for M-series Macs. These improvements make llama.cpp a more versatile tool for developers.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9686 Release Expands Platform Support
The b9686 release of llama.cpp focuses on enhancing compatibility across a wide array of systems, though it doesn't introduce major new features. This update includes ROCm 7.2 support on Ubuntu x64, providing a significant boost for AMD GPU users who prefer alternatives to NVIDIA's CUDA. Developers can now utilize llama.cpp on various configurations, including macOS, Linux, Windows, and openEuler, ensuring they have the tools needed for AI inference tasks. While the release lacks groundbreaking changes, it strengthens llama.cpp's reputation as a flexible and accessible tool for AI developers working on different hardware setups.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9692 Release Expands Platform Support
The latest b9692 release of llama.cpp continues its trend of broadening platform compatibility, now supporting a wide array of systems including macOS, Linux, Windows, and openEuler. Notably, this update includes support for ROCm 7.2 on Ubuntu x64, which is significant for AMD GPU users seeking alternatives to NVIDIA's CUDA. The release also maintains support for Vulkan and OpenVINO across different environments, ensuring flexibility for developers working with diverse hardware. While no new model architectures are introduced, this update solidifies llama.cpp's position as a versatile inference runtime across various environments.
llama.cpp Releases
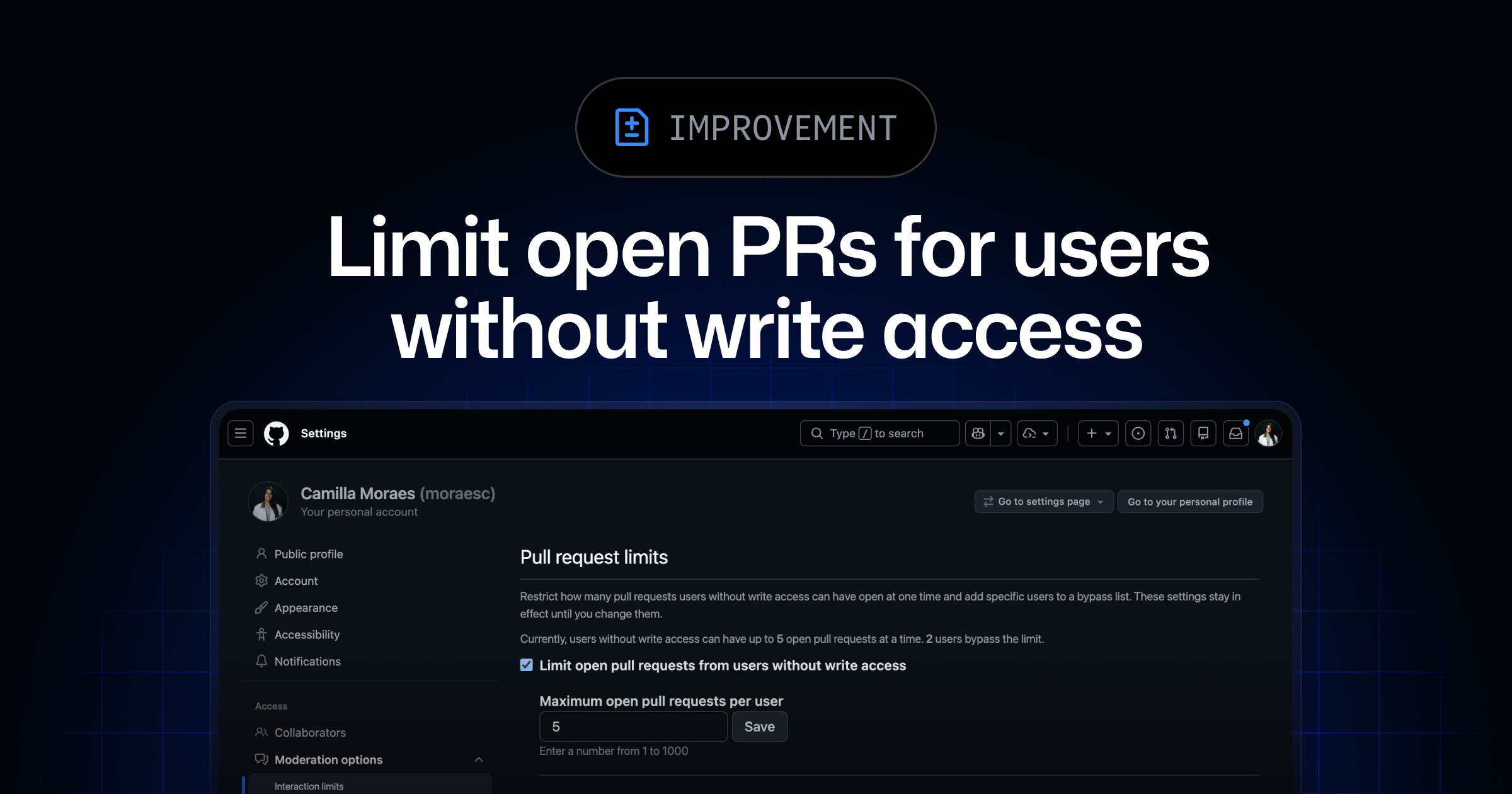 © GitHub Changelog
© GitHub ChangelogOpen Sourcecoding
GitHub Limits Open Pull Requests for Non-Writers
GitHub has introduced a new feature allowing repository maintainers to set a cap on the number of open pull requests from users without write access. This change aims to streamline the management of contributions by reducing the clutter of low-quality or drive-by pull requests. Maintainers can also designate trusted contributors who can exceed this limit without needing full collaborator access. This update is designed to help maintainers focus on meaningful contributions and reduce unnecessary review and CI overhead.
GitHub Changelog
 © Hugging Face Blog
© Hugging Face BlogOpen Sourceagents
Strands Robots SDK Integrates LeRobot for Seamless Robotics
The Strands Robots SDK, an open-source toolkit from AWS, simplifies the process of deploying AI models from the Hugging Face Hub to robot hardware. By integrating the LeRobot stack as AgentTools, developers can now create a single agent that handles simulation, policy inference, and deployment to physical robots with minimal code changes. This integration allows for seamless coordination across multiple robots using a peer mesh network. The SDK's ability to maintain consistent dataset formats between simulation and hardware ensures that developers can easily transition from testing to real-world applications.
Hugging Face Blog
Open Sourcemodels
llama.cpp b9653 Release Expands Platform Support
The latest b9653 release of llama.cpp continues its trend of broadening platform compatibility, notably adding Vulkan support for Ubuntu and Windows, and ROCm 7.2 for Ubuntu x64. While KleidiAI support for macOS Apple Silicon is disabled, the release still offers a wide array of builds across macOS, Linux, Windows, and openEuler. This update doesn't introduce new models or quantization methods but focuses on making llama.cpp more accessible across diverse hardware configurations. Developers can now leverage these enhancements to optimize AI inference on a wider range of systems.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9654 Release Expands Platform Support
The latest b9654 release of llama.cpp continues its trend of broadening platform compatibility, though without major new features. Notably, the release includes support for ROCm 7.2 on Ubuntu x64, which is significant for AMD GPU users seeking alternatives to NVIDIA's CUDA. While KleidiAI support on macOS Apple Silicon is disabled, the release still covers a wide array of systems, including Windows with CUDA 12 and 13 DLLs. This update reinforces llama.cpp's commitment to being a versatile inference runtime across diverse hardware configurations.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9658 Release Expands Platform Support
The b9658 release of llama.cpp marks another step in broadening its compatibility across different systems, now featuring ROCm 7.2 support on Ubuntu x64. This update continues to offer extensive support for macOS, Windows, and Linux, with specific builds for Vulkan and SYCL. Although there are no new model architectures introduced, the release strengthens llama.cpp's role as a versatile inference runtime for a variety of hardware setups. Developers can now utilize llama.cpp more effectively, leveraging its enhanced platform support to optimize AI development across diverse environments.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9659 Release Expands Platform Support
The latest b9659 release of llama.cpp continues its trend of broadening platform compatibility, adding support for a variety of systems including Ubuntu with ROCm 7.2 and Windows with CUDA 12 and 13. This update ensures that developers working on diverse hardware configurations can leverage llama.cpp's capabilities more effectively. Notably, the inclusion of Vulkan support across several operating systems highlights a commitment to versatile GPU acceleration. While no new model architectures are introduced, this release solidifies llama.cpp's position as a flexible inference runtime for a wide range of environments.
llama.cpp Releases
Open Sourcecoding
b9663 Release Enhances SYCL and Platform Support
The b9663 release of llama.cpp brings notable enhancements, particularly in SYCL support, including operations like EXPM1 and comprehensive unit testing for FLOOR, TRUNC, and ROUND functions. This update also addresses conflicts and introduces new unit test cases for repeat and concat operations. With expanded platform support across macOS, Linux, Windows, and openEuler, this release ensures broader compatibility and performance improvements. While no groundbreaking features are introduced, the update solidifies llama.cpp's position as a versatile tool for developers across various systems.
llama.cpp Releases
Open Sourcecoding
llama.cpp b9622 Release Enhances Vulkan Support
The b9622 release of llama.cpp significantly boosts Vulkan capabilities, particularly for non-contiguous unary and glu operations. By refining index calculations with fastdiv and merging unary operations into a single file, the update enhances both performance and code efficiency. It also tackles a compiler bug and resolves earlier conflicts, ensuring smoother functionality across a broad spectrum of hardware setups. While this update doesn't introduce revolutionary features, it strengthens llama.cpp's role as a flexible tool for developers working with diverse hardware, including macOS, Linux, Windows, and openEuler.
llama.cpp Releases
Open Sourcecoding
llama.cpp b9624 Release Expands Platform Support
The b9624 release of llama.cpp enhances its utility by introducing build-time gzip compression, which can optimize performance through reduced file sizes. This update continues to cater to developers working on various systems, including macOS, Linux, Windows, and openEuler, with specific builds for architectures like arm64 and x64. The inclusion of ROCm 7.2 for Ubuntu x64 and CUDA 12 and 13 for Windows x64 highlights its adaptability to different hardware environments. While there are no new model architectures, the release strengthens llama.cpp's role as a flexible tool for developers needing compatibility across diverse setups.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9625 Release Expands Platform Support
The latest b9625 release of llama.cpp continues its trend of broadening platform compatibility, though without any groundbreaking new features. Notably, it includes support for ROCm 7.2 on Ubuntu x64, which is significant for AMD GPU users seeking alternatives to NVIDIA's CUDA. The release also maintains a wide array of builds across macOS, Linux, Windows, and openEuler, though some configurations like KleidiAI on Apple Silicon remain disabled. While this update doesn't introduce new models or quantization methods, it solidifies llama.cpp's role as a versatile inference runtime across diverse systems.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9596 Release Expands Platform Support
The b9596 release of llama.cpp marks another step in broadening its compatibility, with ROCm 7.2 now supported on Ubuntu x64, enhancing the experience for AMD GPU users. This update helps close the performance gap with NVIDIA's CUDA, making llama.cpp a more attractive option for developers using AMD hardware. Although features like KleidiAI on macOS Apple Silicon are still disabled, the release underscores llama.cpp's commitment to becoming a versatile tool across different systems. Developers can now tap into improved performance on a wider array of hardware, though some expected features remain on the horizon.
llama.cpp Releases
Open Sourcemodels
Llama.cpp b9564 Release Enhances WebGPU Support
The b9564 release of llama.cpp marks a notable enhancement in WebGPU capabilities, specifically through the implementation of 2D workgroups for operations like scale, binary, and unary functions. This update is designed to boost performance across macOS, Linux, and Windows systems. While the KleidiAI feature on Apple Silicon remains inactive, the release broadens hardware compatibility, including Vulkan and ROCm 7.2 support on Ubuntu. By refining these technical aspects, llama.cpp becomes a more flexible tool for developers dealing with a range of computing environments, making it a valuable asset for those working with CUDA and other advanced configurations.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9567 release expands platform support
The b9567 release of llama.cpp continues its trend of broadening platform compatibility, though with some notable exceptions. While macOS Apple Silicon users see KleidiAI support disabled, the release strengthens its Linux offerings with ROCm 7.2 and Vulkan support on Ubuntu. Windows users benefit from CUDA 12 and 13 DLLs, enhancing GPU performance. However, some features like SYCL on Windows and macOS remain disabled, indicating ongoing development challenges. This release reflects llama.cpp's commitment to becoming a versatile inference runtime across diverse hardware setups.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9570 Release Expands Platform Support
The b9570 release of llama.cpp continues to broaden its platform compatibility, notably adding support for ROCm 7.2 on Ubuntu x64, which enhances performance for AMD GPU users. While KleidiAI support on Apple Silicon is disabled, the release maintains a strong focus on diverse operating systems, including Windows and openEuler. This update doesn't introduce new models but strengthens llama.cpp's position as a versatile inference runtime across multiple architectures. Users can now leverage improved GPU support, making it a more attractive option for developers working with non-NVIDIA hardware.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9571 Release Expands Platform Support
The latest b9571 release of llama.cpp continues its trend of broadening platform compatibility, notably adding support for ROCm 7.2 on Ubuntu x64. This update ensures that AMD GPU users can leverage llama.cpp more effectively, narrowing the gap with NVIDIA's CUDA. The release also maintains a focus on diverse operating systems, including macOS, Windows, and openEuler, though some features like KleidiAI on Apple Silicon remain disabled. This iteration doesn't introduce new models but solidifies llama.cpp's position as a versatile inference runtime across multiple environments.
llama.cpp Releases
 © Hugging Face Blog
© Hugging Face BlogOpen Sourceagents
OpenEnv Gains Open Source Community Support
OpenEnv is evolving into a pivotal open-source tool for agentic reinforcement learning (RL), now backed by a coalition of major AI organizations including Meta-PyTorch, Nvidia, and Hugging Face. This initiative aims to standardize the interface between RL environments and trainers, promoting interoperability and efficiency. By serving as a common socket for various RL components, OpenEnv facilitates seamless integration across different ecosystems. This move is set to enhance the development of specialized models and harnesses, making RL more accessible and efficient for the open-source community.
Hugging Face Blog
Open Sourcemodels
llama.cpp b9533 release expands platform support
The b9533 release of llama.cpp continues its focus on enhancing platform compatibility, though some features are notably absent. While macOS Apple Silicon users will find KleidiAI support disabled, the release introduces Vulkan support for both Ubuntu and Windows, and keeps CUDA support updated with new DLLs for Windows. The addition of ROCm 7.2 for Ubuntu x64 is particularly important for AMD GPU users, helping to close the gap with NVIDIA's CUDA. This update is more about refining existing capabilities and ensuring that llama.cpp runs smoothly across various environments, rather than unveiling new model architectures.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9535 release expands platform support
The b9535 release of llama.cpp continues to broaden its platform compatibility, though some features remain unavailable. While macOS Apple Silicon users won't see KleidiAI support this time, the release introduces Vulkan support for both Ubuntu and Windows, offering more options for GPU utilization. The addition of ROCm 7.2 for Ubuntu x64 marks a significant step towards better AMD GPU support, helping to close the gap with NVIDIA's CUDA. However, features like SYCL support are still not enabled, indicating areas where development is ongoing. This release reflects llama.cpp's ongoing efforts to become a versatile inference runtime across a wide range of hardware setups.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9537 Release Expands Platform Support
The b9537 release of llama.cpp continues its trend of broadening platform compatibility, though with some notable exceptions. While macOS Apple Silicon users see KleidiAI support disabled, the release strengthens its Linux offerings with ROCm 7.2 and Vulkan support across multiple architectures. Windows users benefit from CUDA 12 and 13 DLLs, enhancing GPU performance options. Despite some disabled features, this update demonstrates llama.cpp's commitment to being a versatile inference runtime across diverse systems, though it remains a work in progress for certain configurations.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9538 Release Expands Platform Support
The latest b9538 release of llama.cpp continues its trend of broadening platform compatibility, notably adding support for ROCm 7.2 on Ubuntu x64. This update ensures that AMD GPU users can leverage llama.cpp more effectively, narrowing the gap with NVIDIA's CUDA. While some features like KleidiAI on Apple Silicon remain disabled, the release still marks a significant step in making llama.cpp a versatile tool across different hardware setups. The inclusion of Vulkan support on various operating systems further enhances its utility for developers looking to optimize performance across different hardware configurations.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9542 Release Expands Platform Support
The latest b9542 release of llama.cpp continues its trend of broadening platform compatibility, though with some notable exceptions. While macOS Apple Silicon support remains robust, the KleidiAI feature is disabled, indicating a shift in focus. On Windows, the inclusion of CUDA 12 and 13 DLLs highlights a commitment to supporting NVIDIA's latest technologies. However, some features like SYCL on Windows and macOS remain disabled, suggesting ongoing development challenges. This release reflects llama.cpp's strategy of incremental platform expansion while navigating technical hurdles.
llama.cpp Releases
Open Sourcecoding
llama.cpp b9503 release focuses on Gemma 4 fix
The b9503 release of llama.cpp addresses a technical issue with the Gemma 4 audio projector embedding size, enhancing its functionality. By removing the projection_dim from clip_n_mmproj_embd, the update streamlines the codebase. This release ensures better compatibility across macOS, Linux, and Windows, with specific builds for Apple Silicon, ROCm 7.2, and CUDA 12 and 13. While it doesn't introduce new features, the update reflects a commitment to improving the software's reliability and performance. This release is a technical refinement, focusing on stability rather than groundbreaking changes.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9504 release expands platform support
The b9504 release of llama.cpp continues to broaden its reach, enhancing compatibility across multiple environments. This update notably includes support for Ubuntu with ROCm 7.2, which boosts performance for AMD GPU users. While features like KleidiAI on macOS and SYCL on Windows are not yet active, the release still represents a significant step in making llama.cpp a more adaptable tool for developers. By focusing on expanding compatibility and improving the runtime experience, this update strengthens llama.cpp's position as a versatile option for developers working with different systems.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9505 release expands platform support
The b9505 release of llama.cpp continues its trend of broadening compatibility across various systems, though with some notable exceptions. While macOS Apple Silicon users see KleidiAI support disabled, the release strengthens its presence on Windows with CUDA 12 and 13 DLLs, and extends Vulkan support to more environments. The inclusion of ROCm 7.2 for Ubuntu x64 users further narrows the gap between AMD and NVIDIA GPU support. This update underscores llama.cpp's commitment to being a versatile inference runtime, though some features remain disabled, indicating ongoing development challenges.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9512 Release Expands Platform Support
The b9512 release of llama.cpp marks another step in broadening its platform reach, though not without some limitations. While support for KleidiAI on macOS Apple Silicon is currently disabled, the update enhances Ubuntu's capabilities with ROCm 7.2 and Vulkan support. Windows users gain improved GPU compatibility through the inclusion of CUDA 12 and 13 DLLs. Despite these advancements, certain features like SYCL support remain inactive. This release demonstrates llama.cpp's ongoing efforts to be a versatile inference runtime, though some areas still need attention.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9515 Release Enhances Code Efficiency
The b9515 release of llama.cpp enhances code efficiency by consolidating duplicated imatrix code into a single common loader. This update also reintroduces LLAMA_TRACE and implements an early exit for missing metadata during quantization. While there are no groundbreaking new features, the release supports a wide range of platforms, including macOS, Linux, Windows, and openEuler, with specific builds for Vulkan, ROCm, and CUDA. This update is a step towards making the codebase more maintainable and efficient for developers, ensuring smoother operations across various environments.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9518 release expands platform support
The b9518 release of llama.cpp continues its trend of broadening platform support, with ROCm 7.2 now available for Ubuntu x64, offering AMD GPU users improved performance options. Although features like KleidiAI on macOS Apple Silicon are still disabled, the release provides a wide array of builds across macOS, Linux, Windows, and openEuler. This update doesn't bring new models or quantization methods but focuses on making llama.cpp more versatile across different hardware configurations. The release highlights llama.cpp's commitment to being a flexible inference runtime for various systems.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9489 release enhances CUDA support
The b9489 release of llama.cpp brings notable improvements for CUDA users, specifically by reserving space for quantized key-value caches at startup. This update also addresses previous feedback and removes certain assertions in the ggml-cuda.cu file, enhancing the CUDA experience. While it doesn't introduce new models or quantization techniques, the release continues to refine the platform's compatibility across macOS, Linux, and Windows. With ROCm 7.2 and KleidiAI support, llama.cpp is becoming a more robust tool for developers working with CUDA and other environments. This iteration is a step towards making llama.cpp a more versatile and efficient tool for AI development.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9490 Release Expands Platform Support
The latest b9490 release of llama.cpp continues its trend of broadening platform compatibility, though with some notable exceptions. While macOS Apple Silicon users see KleidiAI support disabled, the release strengthens its Linux offerings with Vulkan and ROCm 7.2 support on Ubuntu. Windows users benefit from CUDA 12 and 13 DLLs, enhancing GPU performance options. Despite some features being disabled, this update demonstrates llama.cpp's commitment to being a versatile inference runtime across diverse systems.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9493 Release Expands Platform Support
The b9493 release of llama.cpp continues to broaden its platform reach, notably integrating ROCm 7.2 for Ubuntu x64, which offers better support for AMD GPU users. Although features like KleidiAI on macOS Apple Silicon remain inactive, the update emphasizes extending functionality across various systems, including Vulkan support for both Ubuntu and Windows. While no new models are introduced, this release strengthens llama.cpp's role as a versatile inference runtime across multiple operating systems. Developers can now take advantage of improved GPU support, making it a more inclusive tool for those working outside the NVIDIA ecosystem.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9494 release expands platform support
The b9494 release of llama.cpp continues its trend of broadening platform compatibility, though with some notable exceptions. While macOS Apple Silicon users see KleidiAI support disabled, the release adds Vulkan support for Ubuntu and Windows, and maintains CUDA support with updated DLLs for Windows. The inclusion of ROCm 7.2 for Ubuntu x64 is a significant step for AMD GPU users, ensuring they are not left behind in the AI development race. This update solidifies llama.cpp's position as a versatile tool across diverse operating systems, though some features remain disabled, indicating ongoing development challenges.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9495 release enhances platform support
The b9495 release of llama.cpp introduces significant updates, particularly with the qwen35 model now using post-norm hidden states for MTP. This version also changes 'pre_norm' to 'nextn', signaling a shift in the framework's approach. Although features like KleidiAI on macOS Apple Silicon are still disabled, the update broadens compatibility, notably adding support for Ubuntu with ROCm 7.2 and Windows with CUDA 12 and 13. These enhancements make llama.cpp more adaptable for developers working on diverse systems, improving its utility and performance.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9496 release expands platform support
The b9496 release of llama.cpp continues to broaden its platform compatibility, although some features are notably absent. MacOS Apple Silicon users will find KleidiAI support disabled, while Ubuntu gains strength with ROCm 7.2 and Vulkan support. Windows users benefit from the inclusion of CUDA 12 and 13 DLLs, which enhance GPU performance options. Despite certain features being disabled, this release highlights llama.cpp's ongoing commitment to being a versatile inference runtime across diverse systems. The focus remains on improving accessibility and performance across various hardware configurations.
llama.cpp Releases
 © Google Research Blog
© Google Research BlogOpen Sourceresearch
Google Open Sources AI Hydrology Model for Flood Forecasting
Google has open-sourced its advanced AI-based hydrology model, aiming to enhance global flood forecasting capabilities. This move allows National Meteorological and Hydrological Services to integrate sophisticated AI tools into their workflows, potentially improving the accuracy and timeliness of flood warnings. By releasing the model on GitHub, Google empowers local experts to refine and adapt the technology using their own data, fostering a more resilient approach to flood management. This initiative democratizes access to cutting-edge forecasting tools, especially benefiting regions with limited resources.
Google Research Blog
 © TechCrunch AI
© TechCrunch AIOpen Sourceagents
Microsoft Introduces Agent Control Specification for AI
Microsoft's new Agent Control Specification (ACS) offers developers a unified way to manage AI agent behavior across various environments. By allowing teams to define specific policies, ACS ensures agents operate within set boundaries, reducing the risk of unintended actions. This open-source standard integrates controls into a common governance layer, making it easier to audit and reuse across different systems. With ACS, developers can maintain consistent oversight, enhancing both security and compliance in AI deployments.
TechCrunch AI
Open Sourcemodels
llama.cpp b9467 Release Expands Platform Support
The latest b9467 release of llama.cpp continues its trend of broadening platform compatibility, notably adding support for ROCm 7.2 on Ubuntu x64. This update ensures that AMD GPU users can leverage llama.cpp more effectively, narrowing the performance gap with NVIDIA's CUDA. While some features like KleidiAI on macOS Apple Silicon remain disabled, the release still marks a significant step in making llama.cpp a versatile tool across diverse hardware configurations. The focus remains on expanding accessibility, though no new model architectures are introduced in this update.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9439 release expands platform support
The b9439 release of llama.cpp continues its trend of broadening platform compatibility, though this update is more about refinement than groundbreaking changes. Notably, the release includes support for ROCm 7.2 on Ubuntu x64, which is significant for AMD GPU users seeking alternatives to NVIDIA's CUDA. While some features like KleidiAI on macOS and SYCL on Windows remain disabled, the release still marks a step forward in making llama.cpp a versatile tool across diverse hardware environments. This update doesn't introduce new models but solidifies llama.cpp's role as a flexible inference runtime.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9441 Release Expands Platform Support
The b9441 release of llama.cpp continues its trend of broadening platform compatibility, though with some notable exceptions. While macOS Apple Silicon users see KleidiAI support disabled, the release adds Vulkan support for Ubuntu and Windows, and introduces ROCm 7.2 for Ubuntu x64, enhancing AMD GPU usability. The update also includes CUDA 12 and 13 DLLs for Windows, ensuring compatibility with the latest NVIDIA technologies. This release demonstrates llama.cpp's commitment to being a versatile inference runtime across diverse hardware, though some features remain disabled, indicating ongoing development challenges.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9444 Release Expands Platform Support
The b9444 release of llama.cpp enhances its reach by supporting a broader range of systems, including macOS, Linux, Windows, and openEuler. A significant addition is the ROCm 7.2 support on Ubuntu x64, which offers AMD GPU users a viable alternative to NVIDIA's CUDA. Although features like KleidiAI on macOS and SYCL on Windows are not yet active, the update emphasizes llama.cpp's role as a flexible inference runtime across different hardware configurations. While no new models are introduced, the release focuses on strengthening the existing infrastructure, making it more accessible for developers working on diverse hardware setups.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9428 Release Enhances Platform Support
The b9428 release of llama.cpp significantly enhances its platform support, addressing key issues and expanding compatibility. This update fixes the s390x release job and introduces multi-thread build capabilities for iOS-Xcode, improving performance. It also broadens support for macOS, Linux, and Windows, with specific enhancements like Vulkan and ROCm 7.2 on Ubuntu, and CUDA on Windows. While some features like KleidiAI on macOS remain disabled, the release demonstrates a commitment to making llama.cpp more accessible and versatile for developers working across different systems.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9430 Release Adds LSX Support
The latest b9430 release of llama.cpp introduces LSX support, optimizing performance for LoongArch architectures. By implementing native intrinsics for fp16 load/store operations and adding LSX implementations for various dot products, the update enhances computational efficiency. This release also includes improvements for macOS, Linux, and Windows platforms, with specific enhancements for Apple Silicon and Vulkan support. While some features remain disabled, the update signifies a step forward in making llama.cpp more versatile across different hardware configurations.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9431 Release Updates macOS and Windows Builds
The b9431 release of llama.cpp brings targeted updates to its build processes, particularly enhancing the iOS-Xcode release job by moving to macOS-26. This update also involves disabling the libcommon build from the xcframework, which may indicate a strategic optimization. On the Windows side, the release includes updates for CUDA 12 and CUDA 13 DLLs, ensuring the software remains compatible with the latest GPU advancements. While no new features are introduced, these changes reflect a commitment to refining performance and maintaining compatibility with current technologies across different operating systems.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9432 Release Expands Platform Support
The b9432 release of llama.cpp continues its trend of broadening platform compatibility, notably adding support for ROCm 7.2 on Ubuntu x64. This update ensures that AMD GPU users can leverage llama.cpp more effectively, narrowing the gap with NVIDIA's CUDA. While some features like KleidiAI on macOS and SYCL on Windows remain disabled, the release still marks a significant step in making llama.cpp a versatile tool across diverse systems. The focus remains on expanding accessibility and performance across different hardware configurations.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9433 release expands platform support
The latest b9433 release of llama.cpp continues its trend of broadening platform compatibility, notably adding support for ROCm 7.2 on Ubuntu x64. This update ensures that AMD GPU users can leverage llama.cpp more effectively, narrowing the gap with NVIDIA's CUDA. While some features like KleidiAI on macOS Apple Silicon remain disabled, the release still marks a significant step in making llama.cpp a versatile tool across diverse systems. The focus remains on expanding accessibility and performance across various hardware configurations, making it a more inclusive choice for developers.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9436 release expands platform support
The b9436 release of llama.cpp continues to broaden its platform compatibility, though some features remain unavailable. MacOS Apple Silicon users will notice that KleidiAI support is disabled, while Ubuntu users benefit from the inclusion of ROCm 7.2 and Vulkan support. Windows users gain enhanced GPU performance options with the addition of CUDA 12 and 13 DLLs. Despite some features like SYCL on Windows and macOS being disabled, the release focuses on making llama.cpp a versatile inference runtime across various systems. This update doesn't introduce new models but refines existing platform support, making it more adaptable for developers.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9437 release enhances platform support
The b9437 release of llama.cpp introduces significant improvements in platform compatibility and user experience. By setting the default value of -ngl to -1, it ensures consistency with other tools, simplifying the setup process for users. This update extends support to a wide range of systems, including macOS with Apple Silicon, Linux with Vulkan, and Windows with CUDA 12 and 13. Although features like KleidiAI on macOS and SYCL on Windows are currently disabled, the release continues to enhance the tool's reach. These changes make llama.cpp a more adaptable and user-friendly option for developers working across different environments.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9389 Release Expands Platform Support
The latest b9389 release of llama.cpp continues its trend of broadening platform compatibility, though with some notable exceptions. While macOS Apple Silicon users see KleidiAI support disabled, the release strengthens its Linux offerings with ROCm 7.2 and Vulkan support. Windows users benefit from updated CUDA DLLs, enhancing performance for CUDA 12 and 13. This release demonstrates llama.cpp's commitment to being a versatile inference runtime across diverse hardware, though some features remain disabled, indicating ongoing development challenges.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9391 release expands platform support
The b9391 release of llama.cpp continues to broaden its platform support, making it more accessible to a diverse range of users. Notably, this update includes support for Ubuntu x64 with ROCm 7.2, which is significant for AMD GPU users seeking alternatives to NVIDIA's CUDA. While some features like KleidiAI on macOS Apple Silicon and SYCL FP32 on Ubuntu are disabled, the release still marks a step forward in making llama.cpp a versatile tool across different operating systems. This update doesn't introduce new models but enhances the existing infrastructure, ensuring more users can leverage llama.cpp's capabilities.
llama.cpp Releases
Open Sourcecoding
Llama.cpp b9393 Release Fixes Audio RMS Norm
The b9393 release of llama.cpp resolves a critical issue with the audio RMS norm in the gemma 4 module, enhancing its stability. This update, with contributions from Sigbjørn Skjæret, impacts a wide array of systems, including macOS, Linux, Windows, and openEuler. It continues to support architectures like Apple Silicon, Vulkan, and ROCm on Ubuntu, ensuring developers can rely on it across different environments. While it doesn't introduce new features, the update focuses on improving performance and compatibility, reinforcing llama.cpp's position as a reliable tool for developers working with diverse hardware configurations.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9395 Release Expands Platform Support
The b9395 release of llama.cpp continues its trend of broadening platform compatibility, though with some notable exceptions. While macOS Apple Silicon users see KleidiAI support disabled, the release strengthens its Linux offerings with Vulkan and ROCm 7.2 support on Ubuntu. Windows users benefit from CUDA 12 and 13 DLLs, enhancing GPU performance. However, some features like SYCL support remain inactive on certain systems. This update underscores llama.cpp's commitment to being a versatile inference runtime, though it still has gaps to fill in its platform support.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9400 Release Expands Platform Support
The b9400 release of llama.cpp continues its trend of broadening platform compatibility, though without major new features. Notably, it includes support for ROCm 7.2 on Ubuntu x64, which is significant for AMD GPU users seeking alternatives to NVIDIA's CUDA. The release also maintains a wide array of builds across macOS, Linux, Windows, and openEuler, though some configurations like KleidiAI on macOS and SYCL on Windows remain disabled. This update reinforces llama.cpp's role as a versatile inference runtime, though it doesn't introduce groundbreaking changes.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9331 Release Enhances CI Workflows
The b9331 release of llama.cpp brings a strategic overhaul to its continuous integration workflows, focusing on efficiency by isolating tasks into separate workflows. This update includes the extraction of Android and HIP tasks, alongside the relocation of WebGPU and RPC tasks into distinct workflows. Additionally, the release halts SYCL f16 builds and optimizes pull request jobs by aligning backend paths. While there are no new model architectures introduced, this release aims to streamline development processes and enhance build management across diverse environments.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9333 release expands platform support
The b9333 release of llama.cpp marks a significant expansion in its platform reach, enhancing its utility across various systems. With this update, macOS Apple Silicon users can now leverage KleidiAI, while Ubuntu users benefit from Vulkan and ROCm 7.2 enhancements. Windows compatibility is also improved with the inclusion of CUDA 12 and 13 DLLs, and openEuler architectures are now part of the supported lineup. Although there are no new model architectures in this release, llama.cpp is becoming a more versatile inference runtime, catering to a broader range of hardware configurations.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9351 Release Expands Platform Support
The b9351 release of llama.cpp continues to broaden its platform compatibility, notably integrating ROCm 7.2 on Ubuntu x64, which enhances performance for AMD GPU users. This update also includes KleidiAI support for macOS Apple Silicon, making it easier for developers on M-series Macs to leverage ARM-tuned capabilities. While some features like SYCL FP32 on Ubuntu and Windows remain disabled, the release highlights llama.cpp's commitment to being a versatile inference runtime across diverse systems. This update doesn't introduce new models but strengthens the infrastructure for existing ones.
llama.cpp Releases
 © Hugging Face Blog
© Hugging Face BlogOpen Sourceagents
Reachy Mini Enables Local Speech Processing
Hugging Face has introduced a fully local speech processing setup for the Reachy Mini robot, eliminating the need for cloud services and enhancing privacy. By utilizing a cascaded voice pipeline, users can run speech-to-speech interactions entirely on their own hardware, ensuring that no data leaves their network. This setup leverages components like llama.cpp for LLM and Parakeet-TDT for STT, allowing for customizable and cost-effective speech processing. The move empowers users with full control over their speech processing pipeline, offering flexibility to swap components as new models become available.
Hugging Face Blog
Open Sourcemodels
llama.cpp b9296 Release Expands Platform Support
The latest b9296 release of llama.cpp continues its trend of broadening platform compatibility, making it a versatile tool for developers across various systems. Notably, this update includes support for macOS Apple Silicon with KleidiAI enabled, and expands its reach on Windows with CUDA 12 and 13 DLLs. The inclusion of ROCm 7.2 for Ubuntu x64 further enhances its utility for AMD GPU users. While there are no groundbreaking new features, the release solidifies llama.cpp's position as a go-to runtime for diverse hardware configurations, ensuring developers can leverage its capabilities across a wide array of environments.
llama.cpp Releases
Open Sourcecoding
llama.cpp b9283 Release Fixes Build Issues
The b9283 release of llama.cpp tackles significant build issues, particularly enhancing support for Apple systems and ensuring proper installation of implementation libraries. By adding install functionality for shared libraries, the update prevents runtime errors that previously disrupted operations. Developers using macOS, Windows, and Linux can now expect more reliable performance, with specific improvements for Apple Silicon and KleidiAI. The update also addresses issues with CUDA and ROCm builds, reinforcing llama.cpp's stability. While no new features are introduced, this release is a crucial step in refining the software's cross-environment functionality.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9284 Release Enhances Compatibility
The b9284 release of llama.cpp brings significant improvements to its compatibility and performance across different systems. With ROCm 7.2 now supported on Ubuntu x64, AMD GPU users can expect better performance. The update also resolves potential token collisions in the HybridDNA tokenizer, ensuring smoother text processing. On macOS Apple Silicon, KleidiAI is enabled by default, offering optimized performance without additional configuration. While no new models are introduced, the release strengthens llama.cpp's role as a versatile inference runtime, accommodating a wide range of operating environments.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9289 Release Expands Platform Support
The b9289 release of llama.cpp marks a significant step in broadening its platform reach, making it more accessible for developers working on various systems. This update includes support for macOS Apple Silicon with KleidiAI enabled, enhancing performance on Apple's hardware. Windows users benefit from the addition of CUDA 12 and 13 DLLs, while Vulkan support is now available on both Ubuntu and Windows. The inclusion of ROCm 7.2 for Ubuntu caters to AMD users, offering more flexibility in hardware choices. By extending its compatibility, llama.cpp is becoming a more versatile tool for developers aiming to implement AI solutions across different operating systems.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9292 Release Expands Platform Support
The latest b9292 release of llama.cpp significantly broadens its platform compatibility, making it more accessible to a diverse range of users. With support now extended to macOS Apple Silicon with KleidiAI, Ubuntu with ROCm 7.2, and Windows with CUDA 12 and 13, developers can leverage llama.cpp across more environments than ever before. This update doesn't introduce new models or features but focuses on ensuring that the existing capabilities are available on a wider array of hardware and operating systems. By doing so, llama.cpp continues to position itself as a versatile tool for developers working with AI inference across different platforms.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9294 Release Expands Platform Support
The b9294 release of llama.cpp marks a significant step in broadening its reach across various systems. With the addition of macOS Apple Silicon support, including KleidiAI, and Ubuntu with ROCm 7.2, developers can now utilize llama.cpp's capabilities on a wider array of hardware. Windows users benefit from the inclusion of CUDA 13 support, enhancing performance for NVIDIA GPU users. The update also introduces Vulkan and SYCL support, making it a versatile tool for AI inference. While no new models are introduced, this release focuses on making llama.cpp more accessible and efficient across different hardware configurations.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9273 Release Expands Platform Support
The b9273 release of llama.cpp marks a significant step in broadening its reach, now supporting a wider array of systems. Developers using macOS Apple Silicon can now benefit from KleidiAI, while Ubuntu users gain access to ROCm 7.2, enhancing GPU performance. Windows developers aren't left out, with new support for CUDA 12 and 13, making it easier to integrate llama.cpp into existing workflows. Although no new models are introduced, the focus on improving the runtime environment makes it a more adaptable tool for AI inference. This release underscores llama.cpp's commitment to being a versatile solution for developers seeking robust AI capabilities.
llama.cpp Releases
 © GitHub Changelog
© GitHub ChangelogOpen Sourcecoding
GitHub Copilot for Eclipse Goes Open Source
GitHub has open-sourced its Copilot plugin for Eclipse, marking a significant step in integrating AI-powered tools within the Eclipse ecosystem. By releasing the code under the MIT license, GitHub invites developers to explore, contribute, and innovate on how AI enhances developer experiences in Eclipse. This move not only promotes transparency but also encourages community-driven development, allowing developers to understand and influence the plugin's functionality. With the source code available, developers can now delve into the mechanics of Copilot's features like code completion and agentic workflows, fostering a collaborative environment for future enhancements.
GitHub Changelog
Open Sourcemodels
llama.cpp b9251 Release Expands Platform Support
The b9251 release of llama.cpp marks a significant expansion in its platform capabilities, particularly for macOS Apple Silicon users with KleidiAI now enabled by default. Developers will find enhanced support for Vulkan and ROCm 7.2 on Ubuntu, broadening the tool's applicability across different systems. This update also brings technical refinements such as the addition of ggml_backend_dev_t and a new debug log feature, which improve performance and troubleshooting. While no new models are introduced, the renaming of alloc_compute_meta to reserve_compute_meta and the removal of unused functions streamline the codebase. This release reinforces llama.cpp's role as a versatile tool for developers working with diverse hardware configurations.
llama.cpp Releases
Open Sourcecoding
Llama.cpp b9257 Release Optimizes Vulkan Shader
The b9257 release of llama.cpp enhances the IM2COL shader for Vulkan, boosting performance for developers leveraging this graphics API. This update also refines the codebase with better formatting and additional comments, making it more developer-friendly. With compatibility across platforms like macOS, Linux, Windows, and Android, developers on various systems can take advantage of these improvements. Although there are no new groundbreaking features, the focus on performance optimization and code clarity represents a meaningful progression for the llama.cpp project.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9240 Release Expands Platform Support
The latest b9240 release of llama.cpp continues its trend of broadening platform compatibility, now including support for macOS Apple Silicon with KleidiAI enabled, and expanding Vulkan support across Ubuntu and Windows. This release also integrates ROCm 7.2 for Ubuntu, enhancing performance for AMD GPU users. By adding CUDA 12 and 13 support on Windows, llama.cpp ensures that developers can leverage the latest NVIDIA technologies. This update solidifies llama.cpp's position as a versatile inference runtime across diverse hardware configurations.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9245 Release Expands Platform Support
The latest b9245 release of llama.cpp significantly broadens its platform compatibility, making it more accessible to a diverse range of users. With new builds for macOS, Linux, Windows, and Android, the update includes support for Apple Silicon, Vulkan, ROCm 7.2, and CUDA 13, among others. This expansion means developers can now leverage llama.cpp's capabilities across more environments, enhancing its utility for AI inference tasks. While no new models or quantization methods are introduced, the focus on platform inclusivity marks a notable step forward in making llama.cpp a versatile tool for developers.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9213 Release Expands Platform Support
The latest b9213 release of llama.cpp significantly enhances its reach by supporting a wider array of systems. It now includes macOS Apple Silicon with KleidiAI enabled, alongside configurations for Ubuntu, Windows, and Android. This update also brings Vulkan support to both Ubuntu and Windows, and strengthens compatibility with ROCm 7.2 on Ubuntu, making it more versatile for developers. By accommodating more hardware and software environments, llama.cpp continues to evolve as a flexible tool for those working with AI models.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9219 Release Expands Platform Support
The latest b9219 release of llama.cpp continues its trend of broadening platform compatibility, now including support for macOS Apple Silicon with KleidiAI enabled and a variety of Linux configurations such as Ubuntu with ROCm 7.2 and Vulkan. This update also enhances Windows support with CUDA 12 and 13 DLLs, making it more versatile for developers working across different systems. While there are no groundbreaking new features, the release solidifies llama.cpp's position as a flexible inference runtime for diverse hardware setups. Developers can now leverage these updates to optimize AI model performance across a wider range of devices.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9194 Release Expands Platform Support
The latest b9194 release of llama.cpp continues its trend of broadening platform compatibility, now including support for macOS Apple Silicon with KleidiAI enabled and a variety of Linux and Windows configurations. Notably, it adds Vulkan support for Ubuntu and Windows, as well as ROCm 7.2 for Ubuntu, which is significant for AMD GPU users. This release doesn't introduce new models but focuses on making llama.cpp a versatile tool across different hardware setups. The update is a step forward in ensuring that developers can leverage llama.cpp's capabilities on a wider range of systems without compatibility issues.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9196 Release Expands Platform Support
The b9196 release of llama.cpp marks a significant step in broadening its reach across different hardware environments. With the inclusion of macOS Apple Silicon support, now featuring KleidiAI, and enhanced Vulkan and ROCm 7.2 support on Ubuntu, the update ensures developers have more flexibility. Windows users benefit from the addition of CUDA 12 and 13 support, making it easier to run llama.cpp on NVIDIA hardware. Although no new models are introduced, the focus on expanding runtime compatibility highlights llama.cpp's commitment to being a versatile tool for AI inference. This release makes llama.cpp more accessible to developers working across a variety of systems, reinforcing its role as a go-to inference runtime.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9197 Release Expands Platform Support
The b9197 release of llama.cpp marks another step in broadening its platform compatibility, making it an adaptable choice for developers. This update introduces support for macOS Apple Silicon with KleidiAI enabled, alongside enhanced Vulkan and ROCm 7.2 support on Ubuntu. Windows users gain from the inclusion of CUDA 12 and 13 DLLs, which boost GPU performance. Although no new models are added, the release reinforces llama.cpp's role as a flexible inference runtime, accommodating diverse hardware configurations.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9202 Release Expands Platform Support
The b9202 release of llama.cpp marks a significant step in broadening its reach across different systems. With new support for macOS Apple Silicon featuring KleidiAI, and Vulkan compatibility for both Ubuntu and Windows, developers have more flexibility than ever. The inclusion of ROCm 7.2 for Ubuntu enhances performance for those using AMD GPUs, making it a noteworthy update. While no new model architectures are introduced, the focus on expanding runtime compatibility ensures that llama.cpp can be utilized effectively by a wider range of developers. This release is about making llama.cpp a more versatile tool, accommodating the needs of developers working in diverse computing environments.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9203 Release Expands Platform Support
The b9203 release of llama.cpp enhances its platform compatibility, now supporting systems across macOS, Linux, Windows, and Android. This update introduces Vulkan support for both Ubuntu and Windows, which boosts graphics processing capabilities. The addition of ROCm 7.2 for Ubuntu x64 is a significant improvement for AMD GPU users, offering more flexibility for local inference. While no new models are introduced, this release focuses on making llama.cpp a more adaptable tool across different hardware configurations, ensuring developers have the resources they need for diverse environments.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9181 Release Expands Platform Support
The b9181 release of llama.cpp marks a significant step in enhancing its compatibility across multiple platforms. Apple Silicon users now have access to KleidiAI-enabled builds, while Windows users can leverage the latest CUDA 12 and 13 support. Ubuntu x64 users benefit from the inclusion of ROCm 7.2, which improves performance for AMD GPUs. Although this update doesn't introduce new models, it focuses on making llama.cpp a more adaptable tool for developers working with different hardware and software environments.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9186 Release Expands Platform Support
The latest b9186 release of llama.cpp continues its trend of broadening platform compatibility, now including support for macOS Apple Silicon with KleidiAI enabled, and a variety of Linux configurations such as Ubuntu with Vulkan and ROCm 7.2. This update also enhances Windows support with CUDA 12 and 13 DLLs, making it more versatile for developers working across different environments. While there are no groundbreaking new features, the release solidifies llama.cpp's position as a flexible inference runtime for diverse hardware setups. Developers can now leverage these updates to optimize AI model performance across a wider range of systems.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9189 Release Expands Platform Support
The b9189 release of llama.cpp significantly enhances its reach by supporting more platforms, including macOS, Linux, and Windows. This update introduces KleidiAI support on macOS Apple Silicon, while also expanding Vulkan and ROCm 7.2 capabilities on Ubuntu. Although no new models are introduced, the focus is on improving the runtime environment for developers using diverse hardware setups. By broadening its compatibility, llama.cpp strengthens its position as a flexible tool for AI inference, catering to developers across different systems and use cases.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9190 Release Expands Platform Support
The latest b9190 release of llama.cpp significantly broadens its platform compatibility, making it more accessible for developers across various systems. With new support for macOS Apple Silicon, Ubuntu with ROCm 7.2, and Windows with CUDA 12 and 13, this update ensures that developers can leverage llama.cpp's capabilities on a wider range of hardware. This release doesn't introduce new models but focuses on enhancing the runtime environment, making it a more versatile tool for AI inference. Developers now have more flexibility in choosing their preferred platforms without compromising on performance.
llama.cpp Releases
Open Sourcecoding
llama.cpp b9161 Release Enhances Codex CLI Support
The b9161 release of llama.cpp brings a significant improvement to the Codex CLI by bypassing unsupported Responses tools, which enhances its functionality across different operating systems. This update includes warnings for any skipped tools and reverts the special handling for gpt-oss apply_patch, ensuring smoother operations. With support for macOS, Linux, and Windows, including specific builds like macOS Apple Silicon with KleidiAI and Ubuntu with ROCm 7.2, the release broadens its reach. Windows users benefit from CUDA 12 and CUDA 13 support, making it more versatile. While no new models are introduced, the focus on refining existing capabilities makes llama.cpp more robust and reliable for developers.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9163 Release Expands Platform Support
The b9163 release of llama.cpp marks a significant step in broadening its reach across different hardware environments. With new support for macOS Apple Silicon featuring KleidiAI, and Windows systems now accommodating CUDA 12 and 13 DLLs, developers gain enhanced flexibility. The addition of Vulkan support on both Ubuntu and Windows platforms promises improved performance for users. While no new model architectures are introduced, this update focuses on making llama.cpp a more adaptable tool for developers working with diverse hardware setups.
llama.cpp Releases
Open Sourcecoding
llama.cpp b9169 Release Enhances Compatibility
The b9169 release of llama.cpp brings a series of technical improvements, notably adding chunks and fixing preprocessing for qwen3a. This update also addresses memory management by limiting mtmd_chunk size, preventing excessive memory use. Audio token handling has been corrected, and the set_input case has been re-ordered for better processing. With expanded support for macOS, Linux, and Windows, including KleidiAI on Apple Silicon and ROCm 7.2 on Ubuntu, this release optimizes performance across various systems. While it doesn't introduce new groundbreaking features, these refinements make llama.cpp more robust and adaptable for developers working in diverse computing environments.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9172 Release Expands Platform Support
The latest b9172 release of llama.cpp continues its trend of broadening platform compatibility, now including support for systems ranging from macOS Apple Silicon to Windows with CUDA 13. This update is significant for developers working across diverse environments, as it ensures that llama.cpp can be utilized on nearly any hardware configuration. Notably, the inclusion of ROCm 7.2 for Ubuntu x64 and Vulkan support on various operating systems highlights a commitment to making AI inference more accessible. While there are no groundbreaking new features, this release solidifies llama.cpp's position as a versatile tool for AI developers.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9173 Release Expands Platform Support
The latest b9173 release of llama.cpp continues its trend of broadening platform compatibility, now including support for macOS Apple Silicon with KleidiAI enabled and a variety of Linux configurations such as Ubuntu with ROCm 7.2 and Vulkan. This update also enhances Windows support with CUDA 12 and 13 DLLs, making it more versatile for developers working across different environments. While there are no groundbreaking new features, the release solidifies llama.cpp's position as a flexible inference runtime across diverse hardware setups. Developers can now leverage these updates to optimize performance on their specific systems.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9150 Release Expands Platform Support
The b9150 release of llama.cpp continues its trend of broadening platform compatibility, now including support for macOS Apple Silicon with KleidiAI enabled and a variety of Linux configurations such as Ubuntu with ROCm 7.2 and Vulkan. This update also enhances Windows support with CUDA 12 and 13 DLLs, making it more versatile for developers working across different environments. While there are no groundbreaking new features, the release solidifies llama.cpp's position as a flexible inference runtime for diverse hardware setups. Developers can now leverage these updates to optimize performance across a wider range of systems.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9159 Release Expands Platform Support
The latest b9159 release of llama.cpp significantly broadens its platform compatibility, making it more accessible to a diverse range of users. With new builds for macOS, Linux, Windows, and Android, the update includes support for Apple Silicon, Vulkan, ROCm 7.2, and CUDA 13. This expansion means developers can now leverage llama.cpp across more environments, enhancing its utility for AI inference tasks. While there are no new model architectures, the focus on platform diversity ensures that llama.cpp remains a versatile tool for developers working with different hardware configurations.
llama.cpp Releases
 © TechCrunch AI
© TechCrunch AIOpen Sourcecoding
Clawdmeter: Open Source Dashboard for Claude Code Usage
Clawdmeter is an innovative open source project that turns Claude Code usage statistics into a playful desktop dashboard. Developed by Hermann Haraldsson, this device uses a Bluetooth-connected display to present pixel-art animations alongside token usage data, offering a nostalgic nod to classic hardware gadgets. With over 800 stars on GitHub, Clawdmeter captures the developer community's fascination with tokenmaxxing and the creative potential of AI tools. The project exemplifies how AI can make programming more accessible, enabling even those without embedded development experience to create engaging devices.
TechCrunch AI
Open Sourcecoding
llama.cpp b9129 Release Enhances CPU Fallback
The b9129 release of llama.cpp introduces an adaptive fallback feature for the ggml-zendnn backend, which optimizes performance by switching to the CPU for small batch sizes. This feature is enabled by default, but developers can control it using a new runtime environment variable, allowing them to revert to the original fallback logic if desired. The update supports platforms like macOS with KleidiAI, Windows with CUDA 12 and 13, and Ubuntu with ROCm 7.2, ensuring efficient processing across different systems. This release highlights llama.cpp's focus on enhancing performance and flexibility for developers working with various hardware configurations.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9134 Release Expands Platform Support
The latest b9134 release of llama.cpp continues its trend of broadening platform compatibility, making it a versatile tool for developers across various systems. This update includes support for macOS Apple Silicon with KleidiAI enabled, as well as expanded Vulkan and ROCm 7.2 support on Ubuntu. Windows users benefit from updated CUDA 12 and 13 DLLs, enhancing performance for GPU tasks. While no new models are introduced, the release solidifies llama.cpp's position as a flexible inference runtime across diverse hardware configurations.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9139 Release Expands Platform Support
The b9139 release of llama.cpp continues to enhance its platform reach, now supporting macOS Apple Silicon with KleidiAI enabled and various Linux distributions featuring Vulkan and ROCm 7.2. Windows users gain from the inclusion of CUDA 12 and 13 DLLs, improving compatibility for developers working with different hardware setups. While this update doesn't introduce groundbreaking features, it reinforces llama.cpp's role as a flexible inference runtime. Developers can now deploy llama.cpp across more systems, ensuring its capabilities are accessible to a broader developer base.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9140 Release Expands Platform Support
The latest b9140 release of llama.cpp significantly broadens its platform compatibility, making it more accessible for developers across various systems. With support for macOS Apple Silicon, Ubuntu with ROCm 7.2, and Windows with CUDA 12 and 13, this update ensures that developers can leverage llama.cpp's capabilities on a wider range of hardware. The inclusion of Vulkan and SYCL support further enhances its versatility, catering to both CPU and GPU users. This release doesn't introduce new models but focuses on making llama.cpp a more universal tool for AI inference across different hardware setups.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9144 Release Expands Platform Support
The b9144 release of llama.cpp enhances its adaptability by optimizing for specific hardware setups, particularly through the ggml-webgpu update. This ensures subgroup-matrix paths are utilized only when head dimensions meet certain divisibility conditions, improving efficiency. The release broadens support across macOS, Linux, Windows, and Android, with significant improvements for Apple Silicon, Vulkan, and CUDA environments. By focusing on these enhancements, llama.cpp strengthens its role as a flexible tool for developers working with a wide range of hardware configurations, even if no groundbreaking features are introduced.
llama.cpp Releases
 © Microsoft Research
© Microsoft ResearchOpen Sourcecoding
Microsoft's mimalloc: A Scalable Memory Allocator
Microsoft Research's mimalloc is a high-performance, scalable memory allocator designed to replace traditional malloc and free functions. It stands out with its compact codebase and efficient handling of memory allocation across multiple threads, making it ideal for modern applications with large memory demands. By using thread-local heaps, mimalloc minimizes synchronization needs, enhancing performance in concurrent environments. Its adoption in major services like Bing and integration into platforms like Unreal Engine highlight its effectiveness. This development marks a significant step in optimizing memory management for both small and large-scale applications.
Microsoft Research
Open Sourcemodels
llama.cpp b9118 Release Expands Platform Support
The latest b9118 release of llama.cpp continues its trend of broadening platform compatibility, now including support for a wide array of systems such as macOS, Linux, Windows, and Android. Notably, this update introduces Vulkan support on Ubuntu and Windows, alongside ROCm 7.2 for AMD GPUs, which is a significant step for users seeking alternatives to NVIDIA's CUDA. The inclusion of KleidiAI on Apple Silicon further enhances performance for M-series Macs. While there are no new model architectures, this release solidifies llama.cpp's position as a versatile inference runtime across diverse hardware configurations.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9124 Release Expands Platform Support
The latest b9124 release of llama.cpp enhances its versatility by broadening platform compatibility, making it more accessible for developers. By exposing modalities to the /v1/models endpoint, it allows for more adaptable model deployment. The update includes compatibility with various operating systems, from macOS Apple Silicon to Windows with CUDA 13, and even Ubuntu with ROCm 7.2. This release doesn't introduce new models but reinforces llama.cpp's role as a robust inference runtime across diverse hardware configurations.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9105 Release Enhances CUDA Integration
The b9105 release of llama.cpp brings a notable improvement by directly incorporating cuda/iterator, which enhances the reliability of CUDA operations. This update moves away from the previous reliance on a transient import from cub/cub.cuh, ensuring more stable performance for developers using NVIDIA GPUs. The release continues to support a broad array of platforms, including macOS with KleidiAI enabled, Linux with ROCm 7.2, and Windows with CUDA 12 and 13. While there are no new model architectures introduced, this update reinforces llama.cpp's role as a dependable tool for AI developers working across different hardware environments.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9094 Release Expands Platform Support
The b9094 release of llama.cpp marks a significant expansion in platform support, particularly for macOS and Windows users. With the inclusion of KleidiAI enabled builds for Apple Silicon, macOS users gain enhanced performance without additional configuration. Windows users benefit from the addition of CUDA 12 and 13 support, broadening the scope for GPU-accelerated tasks. This release doesn't introduce new models but focuses on making llama.cpp more accessible and versatile across a wider range of systems, reinforcing its position as a go-to inference runtime for diverse hardware setups.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9097 Release Expands Platform Support
The b9097 release of llama.cpp continues its trend of broadening platform compatibility, now including support for macOS Apple Silicon with KleidiAI enabled and various Linux configurations like Ubuntu with Vulkan and ROCm 7.2. This update also enhances Windows support with CUDA 12 and 13 DLLs, making it more versatile for developers working across different environments. While there are no groundbreaking new features, the release solidifies llama.cpp's position as a flexible inference runtime. Developers can now leverage these updates to optimize performance across a wider range of hardware setups.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9101 Release Expands Platform Support
The b9101 release of llama.cpp marks another step in expanding its platform compatibility, now covering macOS, Linux, Windows, and Android. This update introduces Vulkan support on both Ubuntu and Windows, alongside ROCm 7.2 on Ubuntu, enhancing GPU performance capabilities for developers. Windows users gain from the addition of CUDA 12 and 13 DLLs, which improve GPU utilization. While there are no revolutionary new features, this release reinforces llama.cpp's role as a versatile inference runtime across diverse hardware configurations, making it a reliable choice for developers working in varied environments.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9093 Release Expands Platform Support
The b9093 release of llama.cpp marks a significant step in broadening its platform compatibility, making it more accessible to a diverse range of users. With new builds for macOS, Linux, Windows, and Android, the update ensures that developers can leverage llama.cpp across various hardware configurations, including Apple Silicon, Intel, and ARM architectures. Notably, the addition of ROCm 7.2 for Ubuntu x64 and CUDA 12 and 13 for Windows x64 demonstrates a commitment to supporting both AMD and NVIDIA GPUs. This release doesn't introduce new models but focuses on making llama.cpp a versatile tool for developers working on different systems.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9073 Release Expands Platform Support
The b9073 release of llama.cpp marks a significant expansion in platform compatibility, enhancing its accessibility across various operating systems. With KleidiAI now enabled for macOS Apple Silicon, M-series Mac users can expect improved performance. The update also includes builds for Ubuntu featuring ROCm 7.2 and OpenVINO, alongside Windows versions with CUDA 12 and 13, reflecting a commitment to supporting diverse hardware. This positions llama.cpp as a versatile inference runtime, catering to developers across different environments without introducing new model architectures.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9079 Release Expands Platform Support
The latest b9079 release of llama.cpp continues its trend of broadening platform compatibility, now supporting a wide array of systems including macOS, Linux, Windows, and Android. Notably, it includes builds for macOS Apple Silicon with KleidiAI enabled, and Windows with CUDA 12 and 13 support, enhancing performance for NVIDIA GPU users. This release also introduces Vulkan and ROCm 7.2 support on Ubuntu, making it more versatile for developers working across different hardware configurations. While there are no new model architectures, the focus on expanding platform support ensures that llama.cpp remains a flexible and accessible tool for AI developers.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9081 Release Expands Platform Support
The latest b9081 release of llama.cpp continues its trend of broadening platform compatibility, making it a versatile choice for developers across different systems. Notably, this update includes support for macOS Apple Silicon with KleidiAI enabled, and expands Vulkan support to Ubuntu and Windows platforms. The addition of ROCm 7.2 for Ubuntu x64 users shows a commitment to AMD GPU users, while Windows users benefit from CUDA 12 and 13 support. This release doesn't introduce new models but solidifies llama.cpp's position as a flexible inference runtime across diverse hardware configurations.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9056 Release Expands Platform Support
The latest b9056 release of llama.cpp continues its trend of broadening platform compatibility, now including support for macOS Apple Silicon with KleidiAI enabled and a variety of Linux configurations such as Ubuntu with Vulkan and ROCm 7.2. This update also enhances Windows support with CUDA 12 and 13 DLLs, making it more versatile for developers working across different environments. While there are no groundbreaking new features, the release solidifies llama.cpp's position as a flexible inference runtime across diverse hardware setups. Developers can now leverage these updates to optimize performance on their specific systems, whether they're using Apple Silicon, AMD, or NVIDIA GPUs.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9057 Release Expands Platform Support
The latest b9057 release of llama.cpp continues its trend of broadening platform compatibility, now optimizing for RISC-V CPUs with q1_0 dot support. This update enhances performance across a wide array of systems, including macOS, Linux, Windows, and Android, with specific builds for Apple Silicon, Vulkan, and CUDA environments. Notably, the inclusion of ROCm 7.2 for Ubuntu x64 and CUDA 13 for Windows x64 signifies a commitment to supporting diverse hardware configurations. While no new models are introduced, this release solidifies llama.cpp's position as a versatile inference runtime across multiple architectures.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9058 Release Expands Platform Support
The b9058 release of llama.cpp significantly enhances its reach by supporting more platforms, making it a versatile tool for developers. It now includes KleidiAI support for macOS Apple Silicon, which optimizes performance on Apple's ARM architecture. The update also brings Vulkan support to both Ubuntu and Windows, boosting graphics processing capabilities. With the integration of ROCm 7.2 for Ubuntu, AMD GPU users see improved compatibility, narrowing the gap with NVIDIA. Additionally, Windows users benefit from CUDA 12 and 13 DLLs, catering to NVIDIA GPU needs. This release positions llama.cpp as a more adaptable solution for developers working with diverse hardware setups.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9062 Release Expands Platform Support
The latest b9062 release of llama.cpp continues its trend of broadening platform compatibility, making it a versatile tool for developers across various systems. Notably, this update includes support for macOS Apple Silicon with KleidiAI enabled, as well as expanded Vulkan and ROCm 7.2 support on Ubuntu. Windows users benefit from CUDA 12 and 13 compatibility, enhancing performance for those leveraging NVIDIA GPUs. This release doesn't introduce new models but solidifies llama.cpp's position as a go-to runtime for diverse hardware configurations, ensuring developers can deploy AI models efficiently across a wide array of environments.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9063 Release Expands Platform Support
The b9063 release of llama.cpp marks a significant step in broadening its compatibility across various systems. Notably, it now supports macOS Apple Silicon with KleidiAI enabled, Ubuntu with ROCm 7.2, and Windows with CUDA 13.1. While no new models are introduced, the update focuses on improving the runtime environment for different hardware setups, including Vulkan and SYCL support. This makes llama.cpp a more adaptable tool for developers working with diverse GPU and CPU architectures. By enhancing its functionality for both AMD and NVIDIA users, llama.cpp reinforces its position as a comprehensive inference runtime solution.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9064 Release Expands Platform Support
The latest b9064 release of llama.cpp continues its trend of broadening platform compatibility, making it a versatile choice for developers across different systems. With this update, Apple Silicon users benefit from KleidiAI integration, enhancing performance on M-series Macs. The inclusion of ROCm 7.2 for Ubuntu x64 further levels the playing field for AMD GPU users, while Windows users gain access to CUDA 12 and 13 support. This release doesn't introduce new models but solidifies llama.cpp's position as a go-to runtime for diverse hardware configurations.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9047 release focuses on device memory handling
The b9047 release of llama.cpp enhances how device memory is managed, particularly for GPUs with unknown configurations. By ensuring that memory fit for unknown GPUs is set to zero and maintaining a fallback for non-GPU devices, the update boosts stability and reliability. This release continues to support a broad array of operating systems, including macOS with KleidiAI enabled, Ubuntu with ROCm 7.2, and Windows with CUDA 12 and 13. While it doesn't introduce groundbreaking features, these refinements make llama.cpp a more dependable tool for developers working across different hardware environments.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9030 Release Expands Platform Support
The b9030 release of llama.cpp significantly enhances its platform reach, especially for macOS and Windows users. With KleidiAI now available for Apple Silicon, macOS users can enjoy improved performance without needing extra setup. Windows developers gain from the addition of CUDA 12 and 13, which facilitates better use of NVIDIA GPUs. This update doesn't bring new models but focuses on making llama.cpp more adaptable and functional across a broader array of systems, ensuring developers can utilize its features on their chosen platforms.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9015 Release Expands Platform Support
The b9015 release of llama.cpp marks another step in expanding its reach across diverse systems, now including macOS Apple Silicon with KleidiAI enabled and Ubuntu with ROCm 7.2. This update also brings Vulkan support to both Linux and Windows, enhancing the software's versatility. Windows users benefit from CUDA 12 and 13 support, ensuring compatibility with the latest NVIDIA technologies. While the release doesn't introduce new model architectures, it strengthens llama.cpp's role as a flexible inference runtime for developers working with varied hardware configurations.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9009 Release Expands Platform Support
The latest b9009 release of llama.cpp continues its trend of broadening platform compatibility, now including support for macOS Apple Silicon with KleidiAI enabled and various Linux distributions with Vulkan and ROCm 7.2. This update refines the server's efficiency by avoiding unnecessary checkpoint data host copies, which could enhance performance. While the release doesn't introduce new model architectures, it solidifies llama.cpp's position as a versatile inference runtime across diverse systems. Developers can now leverage these improvements to optimize AI applications on a wider range of hardware configurations.
llama.cpp Releases
Open Sourcecoding
b9014 Release Adds Layer Norm Ops to ggml-webgpu
The b9014 release of llama.cpp enhances ggml-webgpu by integrating layer normalization operations, boosting its shader functionality. This update stabilizes floating point computations with Kahan summation, though it later reverts to the original method for improved efficiency. By eliminating non-contiguous strides, the release optimizes performance on platforms like macOS with KleidiAI, Ubuntu with ROCm 7.2, and Windows with CUDA 12 and 13. These changes make llama.cpp more adaptable and efficient for developers working with a range of hardware setups.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9008 Release Expands Platform Support
The b9008 release of llama.cpp continues its trend of broadening platform support, making it a versatile tool for developers across various systems. This update includes new builds for macOS, Linux, Windows, and Android, with notable additions like Vulkan support on Ubuntu and Windows, and ROCm 7.2 on Ubuntu. By enhancing compatibility with different architectures, including Apple Silicon and Intel on macOS, and CUDA on Windows, llama.cpp is positioning itself as a go-to runtime for diverse hardware environments. While there are no groundbreaking new features, the release solidifies llama.cpp's role as a flexible and accessible inference tool for developers.
llama.cpp Releases
Open Sourceother
b9004 Release for Multiple Platforms
The b9004 release of llama.cpp introduces support for various platforms including macOS, Linux, Android, and Windows.
llama.cpp Releases
Open Sourceother
llama-quant update fixes tensor-type issue
The latest update for llama-quant addresses a tensor-type issue when the default qtype is overridden. This release includes support for various platforms.
llama.cpp Releases
Open Sourceother
New Vulkan Functions Added in Llama.cpp Release
The latest release of Llama.cpp introduces new Vulkan functions for tensor manipulation and updates across multiple platforms.
llama.cpp Releases
Open Sourceimage
vLLM Releases v0.18.2rc0 Update
The v0.18.2rc0 release includes a fix for handling the max_pixels parameter in the PaddleOCR-VL image processor across transformations.
vLLM Releases
Open Sourceother
New Release of llama.cpp Supports Multiple Platforms
The latest release of llama.cpp includes support for various operating systems and architectures, including macOS, Linux, Android, and Windows. This update enhances compatibility for developers working across different environments.
llama.cpp Releases
Open Sourceother
Llama.cpp Updates Hexagon Configuration Options
The latest release of Llama.cpp introduces configurable virtual memory and buffer sizes for Hexagon, along with various enhancements and support for multiple platforms including macOS, Linux, Android, and Windows.
llama.cpp Releases
Open Sourceother
Llama.cpp Updates Vocab Compatibility Checks
The latest release of Llama.cpp includes fixes for vocabulary compatibility checks in the spec example and updates to logging for draft and target model vocabulary mismatches. It supports multiple platforms including macOS, Linux, Android, and Windows.
llama.cpp Releases
 © Together AI Blog
© Together AI BlogOpen Sourceother
Aurora: Open-source RL Framework for Speculative Decoding
Aurora is an open-source reinforcement learning framework that enhances speculative decoding by allowing it to learn from each request it serves, rather than relying on a static setup.
Together AI Blog
 © Google Research Blog
© Google Research BlogOpen Sourceresearch
WAXAL: Open Resource for African Language Speech Tech
Google Research has introduced WAXAL, a large-scale open resource aimed at advancing speech technology for African languages. This initiative seeks to enhance natural language processing capabilities in underrepresented languages.
Google Research Blog
 © Together AI Blog
© Together AI BlogOpen Sourcecoding
CoderForge-Preview: New Open Dataset Released
Together AI has announced the release of CoderForge-Preview, a state-of-the-art open dataset designed for training efficient coding agents.
Together AI Blog
 © Together AI Blog
© Together AI BlogOpen Sourceother
Choosing the Right Open Model for Production
The article provides guidance on selecting open-source models for production by assessing model quality, performance benchmarks, and deployment considerations regarding cost, speed, and accuracy.
Together AI Blog
 © Hugging Face Blog
© Hugging Face BlogOpen Sourceresearch
Kimina-Prover-RL: New Open-Source Theorem Proving Pipeline
Kimina-Prover-RL introduces a novel open-source training pipeline for formal theorem proving in Lean 4, setting new benchmarks for open-source models. By employing a reasoning-then-generation paradigm, the pipeline enhances model explainability and error recovery. The release includes two models, AI-MO/Kimina-Prover-RL-1.7B and AI-MO/Kimina-Prover-RL-0.6B, which achieve state-of-the-art results on the MiniF2F benchmark. This development allows researchers to reproduce experiments and adapt the setup for their own models, marking a significant step forward in formal proof automation.
Hugging Face Blog
 © Replicate Blog
© Replicate BlogOpen Sourcevideo
Open source video model Wan 2.2 released
Replicate has announced Wan 2.2, their fastest and cheapest open source video model to date.
Replicate Blog
Open Sourceother
The Frontier is Open
Together AI has announced the opening of their new platform, allowing developers to access and utilize their AI tools more freely.
Together AI Blog
 © EleutherAI Blog
© EleutherAI BlogOpen Sourceresearch
Common Pile v0.1 Dataset Released
EleutherAI has announced the release of Common Pile v0.1, an 8TB dataset consisting of public domain and openly licensed text.
EleutherAI Blog
 © Replicate Blog
© Replicate BlogOpen Sourcevideo
Fine-tune open-source video models now available
Users can now train their own versions of Tencent's HunyuanVideo for style, motion, and character customization on the Replicate platform.
Replicate Blog
 © Replicate Blog
© Replicate BlogOpen Sourcemodels
FLUX fine-tunes optimization announced
Replicate has improved the speed of running fine-tunes for FLUX, and these optimizations are available as open-source.
Replicate Blog
 © Replicate Blog
© Replicate BlogOpen Sourceother
FLUX Optimizations Released as Open Source
FLUX has been optimized for speed on Replicate, and these improvements have been made available as open-source for further development.
Replicate Blog
 © Replicate Blog
© Replicate BlogOpen Sourceimage
New Open Source Image Model and Tools Released
Replicate has announced an open source frontier image model that allows users to cut objects from videos, along with a new Python web framework developed by Jeremy Howard.
Replicate Blog
 © EleutherAI Blog
© EleutherAI BlogOpen Sourceother
Open Source Pipeline for Auto-Interpretability Released
EleutherAI has announced the development of an open-source pipeline aimed at enhancing the interpretability of sparse autoencoder features.
EleutherAI Blog
 © Replicate Blog
© Replicate BlogOpen Sourceimage
Run Stable Diffusion 3 Locally with ComfyUI
Users can now run Stable Diffusion 3 on their own machines using ComfyUI by executing a few terminal commands. This allows for local experimentation with the model on GPU-powered systems.
Replicate Blog
 © Replicate Blog
© Replicate BlogOpen Sourceother
Replicate Intelligence #1 Overview
The Replicate Blog discusses a DIY implementation of Llama 3, introduces open-source smart glasses, and explores steering language models using dictionary learning techniques.
Replicate Blog
 © Replicate Blog
© Replicate BlogOpen Sourcemusic
Voice Cloning with Open-Source Models
Replicate has introduced fine-tuning for realistic voice cloning (RVC), allowing users to train models on their own datasets from YouTube videos using a simple code interface.
Replicate Blog
© EleutherAI BlogOpen Sourceother
Minetester: Open RL Environment on Minetest
Minetester is introduced as a fully open reinforcement learning environment built on the Minetest platform, along with an overview of its preliminary work.
EleutherAI Blog
© EleutherAI BlogOpen Sourceother
EleutherAI Yearly Retrospective Released
EleutherAI has published a detailed retrospective covering their activities over the past year.
EleutherAI Blog
 © Hugging Face Blog
© Hugging Face BlogOpen Sourcecoding
Hugging Face Introduces Skops for scikit-learn Models
Hugging Face has launched Skops, a new library designed to streamline the process of hosting scikit-learn models on the Hugging Face Hub. This tool allows developers to create detailed model cards, enhancing documentation and collaboration. By integrating Skops, users can easily serialize models, generate configuration files, and push them to the Hub, making them accessible for inference and further development. This release marks a significant step in making machine learning models more shareable and reproducible, particularly for those working with scikit-learn.
Hugging Face Blog
© EleutherAI BlogOpen Sourceother
Open Source Large Language Model for AI Safety
EleutherAI discusses the benefits of releasing a large language model as a means to enhance AI safety. The blog outlines their reasoning behind this belief.
EleutherAI Blog