Open Source
llama.cpp b9686 Release Expands Platform Support
llama.cpp Releaseshigh confidence
Why it matters
- →Expands platform support, making llama.cpp more accessible to diverse developers.
- →Enhances AMD GPU support with ROCm 7.2, offering alternatives to NVIDIA's CUDA.
- →Solidifies llama.cpp's position as a versatile AI inference tool.
The b9686 release of llama.cpp has been announced, focusing on expanding platform support rather than introducing new features. This update includes ROCm 7.2 support on Ubuntu x64, enhancing options for AMD GPU users. The release covers a wide range of platforms, including macOS, Linux, Windows, and openEuler, ensuring broad accessibility for developers. While the update doesn't bring new functionalities, it reinforces llama.cpp's role as a flexible AI inference tool across various systems.
Read originalMore from llama.cpp Releases
Open Sourcecoding
llama.cpp b9684 Release Adds 3D Convolution
The b9684 release of llama.cpp marks a significant enhancement with the integration of 3D convolution, boosting its ability to handle complex data processing tasks. This update also brings optimizations and a cleaner codebase, enhancing overall efficiency. The release extends support across a broad spectrum of platforms, including macOS, Linux, and Windows, with specific configurations like Vulkan, ROCm, and SYCL. By expanding its platform compatibility and functionality, llama.cpp becomes an even more versatile tool for developers tackling diverse AI challenges.
llama.cpp Releases
Open Sourcecoding
llama.cpp b9685 Release Enhances SYCL Support
The b9685 release of llama.cpp brings notable advancements in SYCL support, particularly with the addition of device-to-device memory copy via the SYCL API. This update also refines the detection method for peer-to-peer communication, resolving previous conflicts. While there are no new model architectures introduced, the release enhances the platform's adaptability across macOS, Linux, and Windows. With ROCm 7.2 support on Ubuntu and CUDA 12 and 13 DLLs for Windows, llama.cpp becomes a more robust choice for developers working with diverse hardware configurations. The inclusion of KleidiAI on Apple Silicon further optimizes performance for M-series Macs. These improvements make llama.cpp a more versatile tool for developers.
llama.cpp Releases
Models & Labsmodels
Llama.cpp b9688 Release Enhances Model Management
The latest b9688 release of llama.cpp introduces significant updates to its server capabilities, including a new model management API and real-time SSE updates. These enhancements aim to streamline the deployment and management of AI models, making it easier for developers to integrate and maintain models in various environments. The update also includes a download API and a delete endpoint, providing more control over model assets. While the release doesn't introduce new models, it strengthens the infrastructure, making llama.cpp a more robust choice for developers working with diverse hardware configurations.
llama.cpp Releases
More in Open Source
 © GitHub Changelog
© GitHub ChangelogOpen Sourcecoding
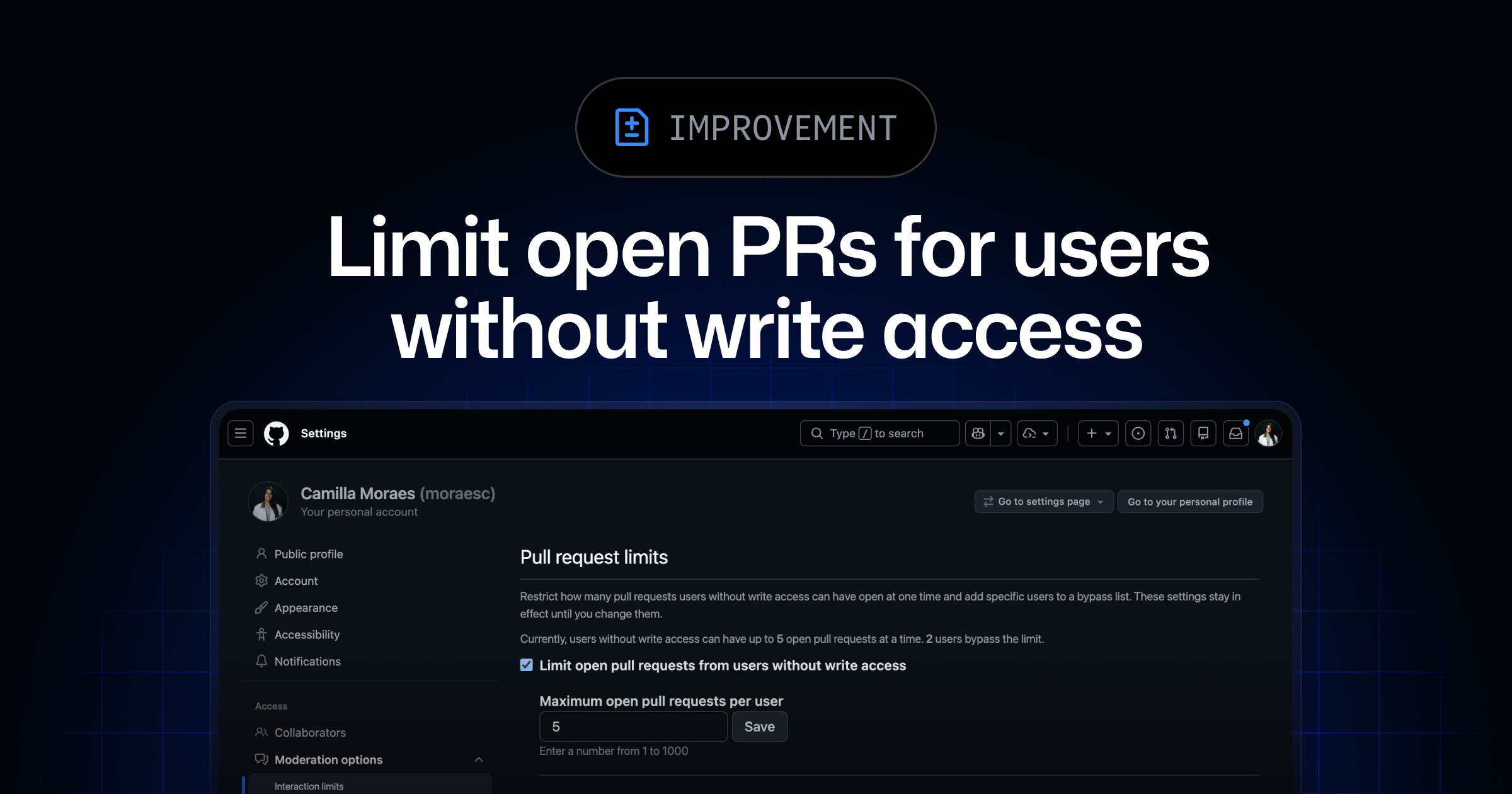
GitHub Limits Open Pull Requests for Non-Writers
GitHub has introduced a new feature allowing repository maintainers to set a cap on the number of open pull requests from users without write access. This change aims to streamline the management of contributions by reducing the clutter of low-quality or drive-by pull requests. Maintainers can also designate trusted contributors who can exceed this limit without needing full collaborator access. This update is designed to help maintainers focus on meaningful contributions and reduce unnecessary review and CI overhead.
GitHub Changelog
 © Hugging Face Blog
© Hugging Face BlogOpen Sourceagents
Strands Robots SDK Integrates LeRobot for Seamless Robotics
The Strands Robots SDK, an open-source toolkit from AWS, simplifies the process of deploying AI models from the Hugging Face Hub to robot hardware. By integrating the LeRobot stack as AgentTools, developers can now create a single agent that handles simulation, policy inference, and deployment to physical robots with minimal code changes. This integration allows for seamless coordination across multiple robots using a peer mesh network. The SDK's ability to maintain consistent dataset formats between simulation and hardware ensures that developers can easily transition from testing to real-world applications.
Hugging Face Blog
 © Hugging Face Blog
© Hugging Face BlogOpen Sourceagents
OpenEnv Gains Open Source Community Support
OpenEnv is evolving into a pivotal open-source tool for agentic reinforcement learning (RL), now backed by a coalition of major AI organizations including Meta-PyTorch, Nvidia, and Hugging Face. This initiative aims to standardize the interface between RL environments and trainers, promoting interoperability and efficiency. By serving as a common socket for various RL components, OpenEnv facilitates seamless integration across different ecosystems. This move is set to enhance the development of specialized models and harnesses, making RL more accessible and efficient for the open-source community.
Hugging Face Blog