Open Source
llama.cpp b9748 release expands platform support
llama.cpp Releaseshigh confidence
Why it matters
- →Expands support for AMD GPUs, reducing reliance on NVIDIA CUDA.
- →Enhances performance options with Vulkan support across platforms.
- →Solidifies llama.cpp's versatility in diverse hardware environments.
The b9748 release of llama.cpp introduces expanded platform support, including ROCm 7.2 for Ubuntu x64, which benefits AMD GPU users by improving compatibility. The update also brings Vulkan support to various platforms, offering developers more performance options. While the release doesn't introduce new model architectures, it strengthens llama.cpp's role as a flexible inference runtime across different hardware setups.
Read originalMore from llama.cpp Releases
Models & Labsmodels
llama.cpp b9745 Release Enhances MTP Support
The latest b9745 release of llama.cpp introduces significant enhancements in multi-threaded processing (MTP) support, particularly with the addition of Step3.5/3.7 flash MTP3. This update includes new APIs like llama_set_mtp_layer_offset and llama_model_n_nextn_layer, which aim to improve the efficiency of multi-head processing. The release also addresses various platform-specific builds, including support for macOS, Linux, Windows, and openEuler, ensuring broader compatibility. While the update doesn't introduce new models, it refines the existing infrastructure, making llama.cpp more robust for developers working with diverse hardware configurations.
llama.cpp Releases
Models & Labsmodels
llama.cpp b9747 release enhances model tracking
The b9747 release of llama.cpp brings a notable improvement with real-time model load progress tracking, enhancing user interaction by offering immediate insights during loading. This update includes server-side improvements such as the addition of a mutex for notify_to_router, which ensures more reliable operations. While there are no new model architectures introduced, the release broadens its reach by supporting platforms like macOS, Linux, and Windows. This makes llama.cpp a more flexible tool for developers working in different environments, although some features like KleidiAI on Apple Silicon are not yet active. The inclusion of ROCm 7.2 and CUDA 12 and 13 DLLs further solidifies its utility across diverse hardware setups.
llama.cpp Releases
Open Sourcemodels
llama.cpp b9750 Release Expands Platform Support
The latest b9750 release of llama.cpp continues its trend of broadening platform compatibility, notably with the inclusion of ROCm 7.2 for Ubuntu x64, which enhances support for AMD GPUs. This update also refines the codebase by implementing a call statement and simplifying certain functions, which could improve performance and maintainability. While KleidiAI support for macOS Apple Silicon is disabled, the release still offers a wide array of builds across macOS, Linux, Windows, and openEuler. This iteration doesn't introduce new models but strengthens llama.cpp's position as a versatile inference runtime across diverse hardware configurations.
llama.cpp Releases
More in Open Source
 © Lev Selector
© Lev SelectorOpen Sourcecoding
Kimi K2.7 and GLM-5.2 Models Released
Moonshot AI and Zhipu AI have released new open weight coding models, Kimi K2.7 and GLM-5.2.
Lev Selector
 © Duncan Rogoff
© Duncan RogoffOpen Sourceagents
Anthropic Releases Open Source Tool for AI Agents
Anthropic has launched a new open-source tool called Claude Code, designed to simplify the creation of AI agents. This tool allows users to build and deploy AI agents without needing to write code or manage servers, making it accessible to a broader audience. The process involves an interactive setup that defines success criteria and schedules tasks, all managed in the cloud. This release could democratize AI agent development, enabling more people to experiment and innovate with AI technologies without technical barriers.
Duncan Rogoff
 © GitHub Changelog
© GitHub ChangelogOpen Sourcecoding
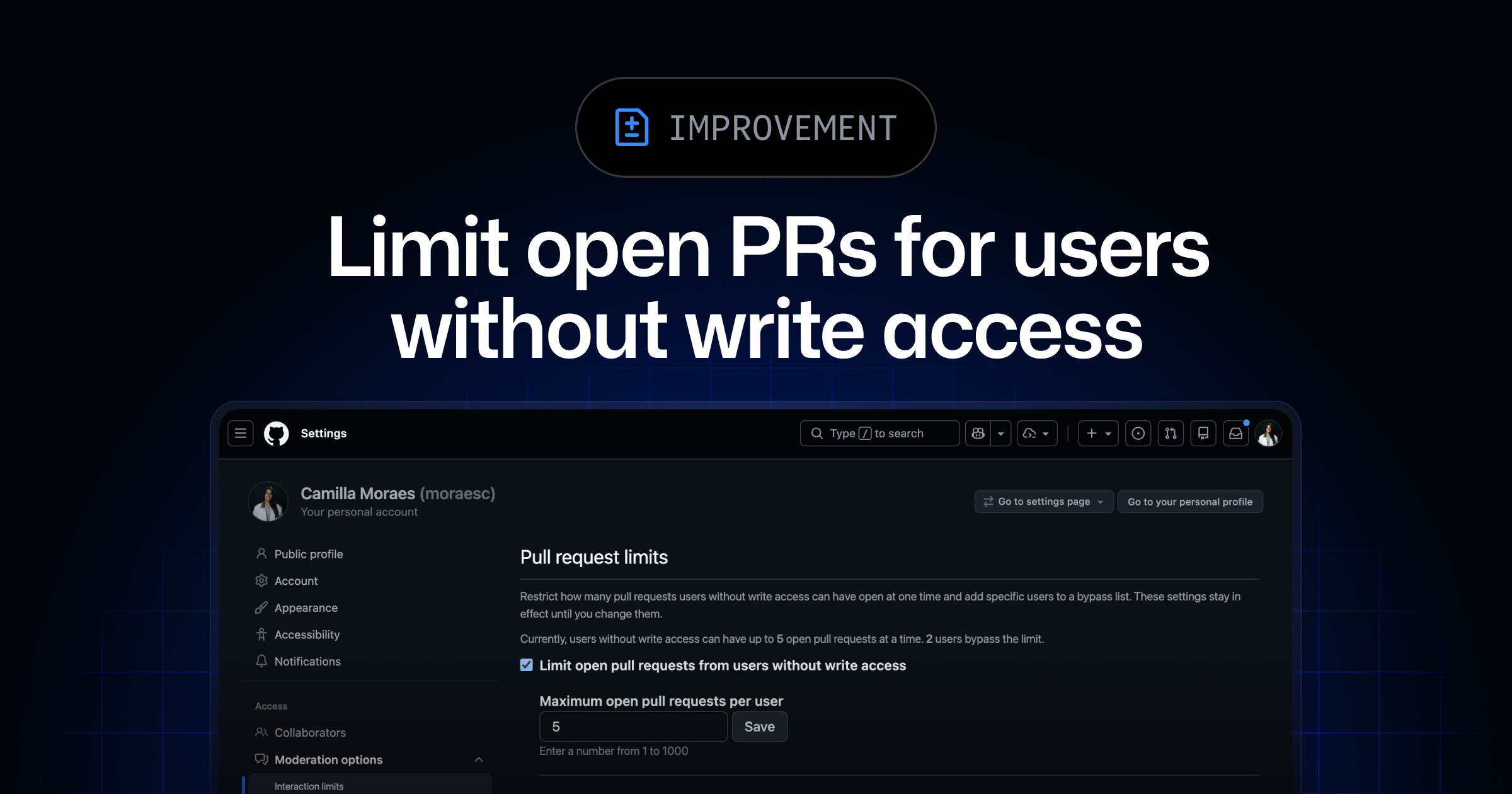
GitHub Limits Open Pull Requests for Non-Writers
GitHub has introduced a new feature allowing repository maintainers to set a cap on the number of open pull requests from users without write access. This change aims to streamline the management of contributions by reducing the clutter of low-quality or drive-by pull requests. Maintainers can also designate trusted contributors who can exceed this limit without needing full collaborator access. This update is designed to help maintainers focus on meaningful contributions and reduce unnecessary review and CI overhead.
GitHub Changelog