Models & Labs
Claude Opus 4.8 Fast Mode Preview on GitHub Copilot
GitHub Changeloghigh confidence
Why it matters
- →Faster output speeds enhance developer productivity in interactive coding environments.
- →The reduced cost of fast mode makes advanced AI tools more accessible.
- →Gradual rollout across platforms ensures broad accessibility for various user needs.
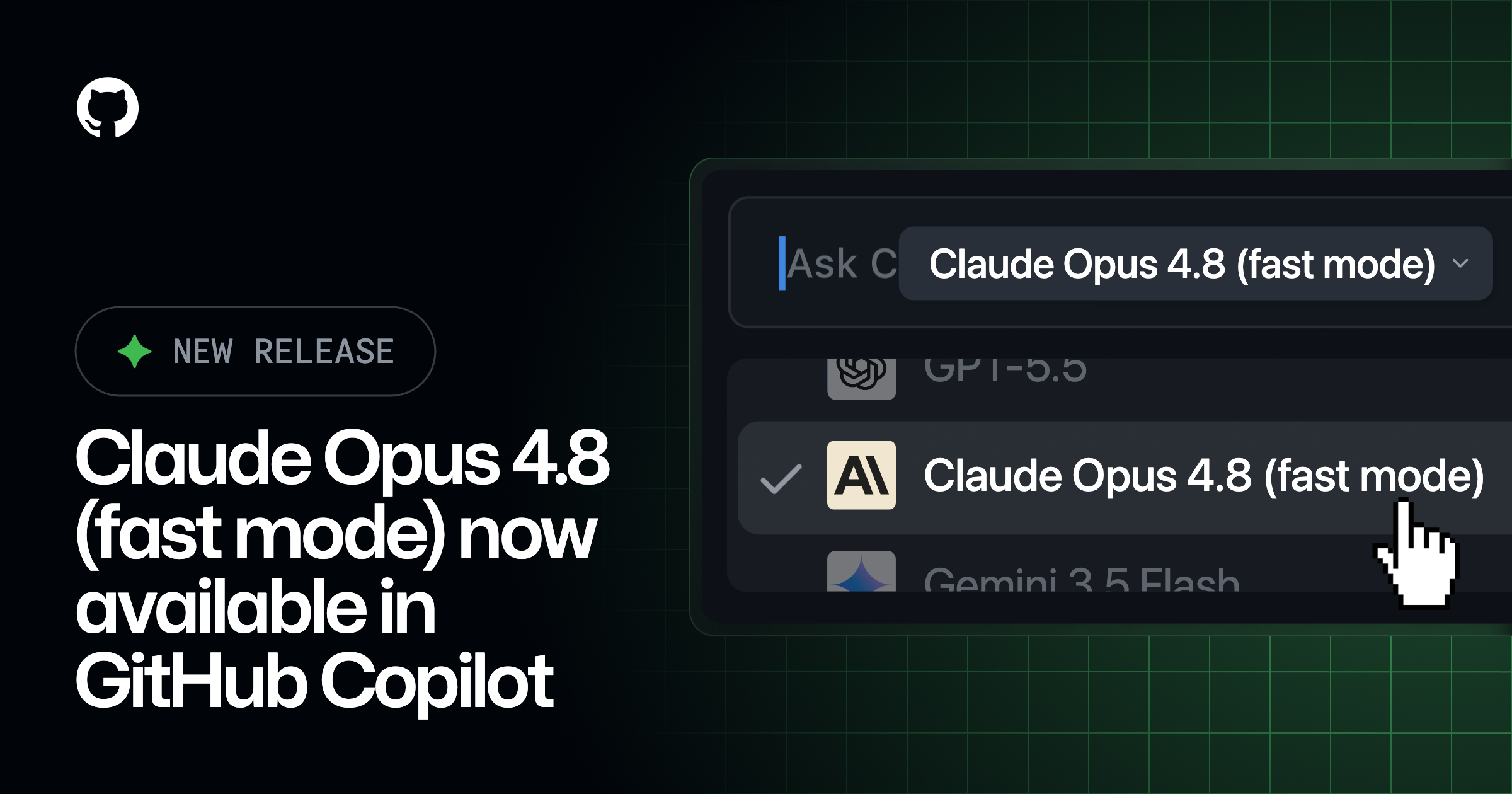
GitHub Copilot has introduced a preview of Claude Opus 4.8 in fast mode, offering significantly faster output speeds while maintaining the model's intelligence. This new mode is designed for interactive coding and agentic workflows, where quick response times are essential. Although it is more cost-effective than previous fast modes, it is still more expensive than the standard Claude Opus 4.8. The feature is available to Copilot Pro+, Max, Business, and Enterprise users across multiple platforms, with a gradual rollout planned.
Read originalMore from GitHub Changelog
 © GitHub Changelog
© GitHub ChangelogModels & Labsbusiness
GitHub Enhances AI Adoption Metrics for Enterprises
GitHub has expanded its Copilot usage metrics API to include total pull requests merged by AI adoption phase, offering a more comprehensive view of user engagement. Previously, only per-user averages were available, but now enterprise administrators and organization owners can see the total number of pull requests merged daily by users in each adoption phase. This enhancement allows for better analysis of how AI adoption impacts development throughput and user behavior. By providing both total and average metrics, GitHub enables a deeper understanding of AI's role in software development processes.
GitHub Changelog
 © GitHub Changelog
© GitHub ChangelogModels & Labscoding
MAI-Code-1-Flash Now Available for GitHub Copilot
Microsoft AI's MAI-Code-1-Flash model is now generally available for GitHub Copilot Business and Enterprise users, marking a significant step in optimizing coding workflows. This model is designed to deliver fast, low-latency responses, making it ideal for high-volume, iterative coding tasks where speed is crucial. By integrating this model, GitHub aims to enhance the efficiency of Copilot users, particularly in enterprise environments. Administrators need to enable this feature in settings, highlighting a focus on customizable enterprise solutions.
GitHub Changelog
 © GitHub Changelog
© GitHub ChangelogCoding Toolscoding
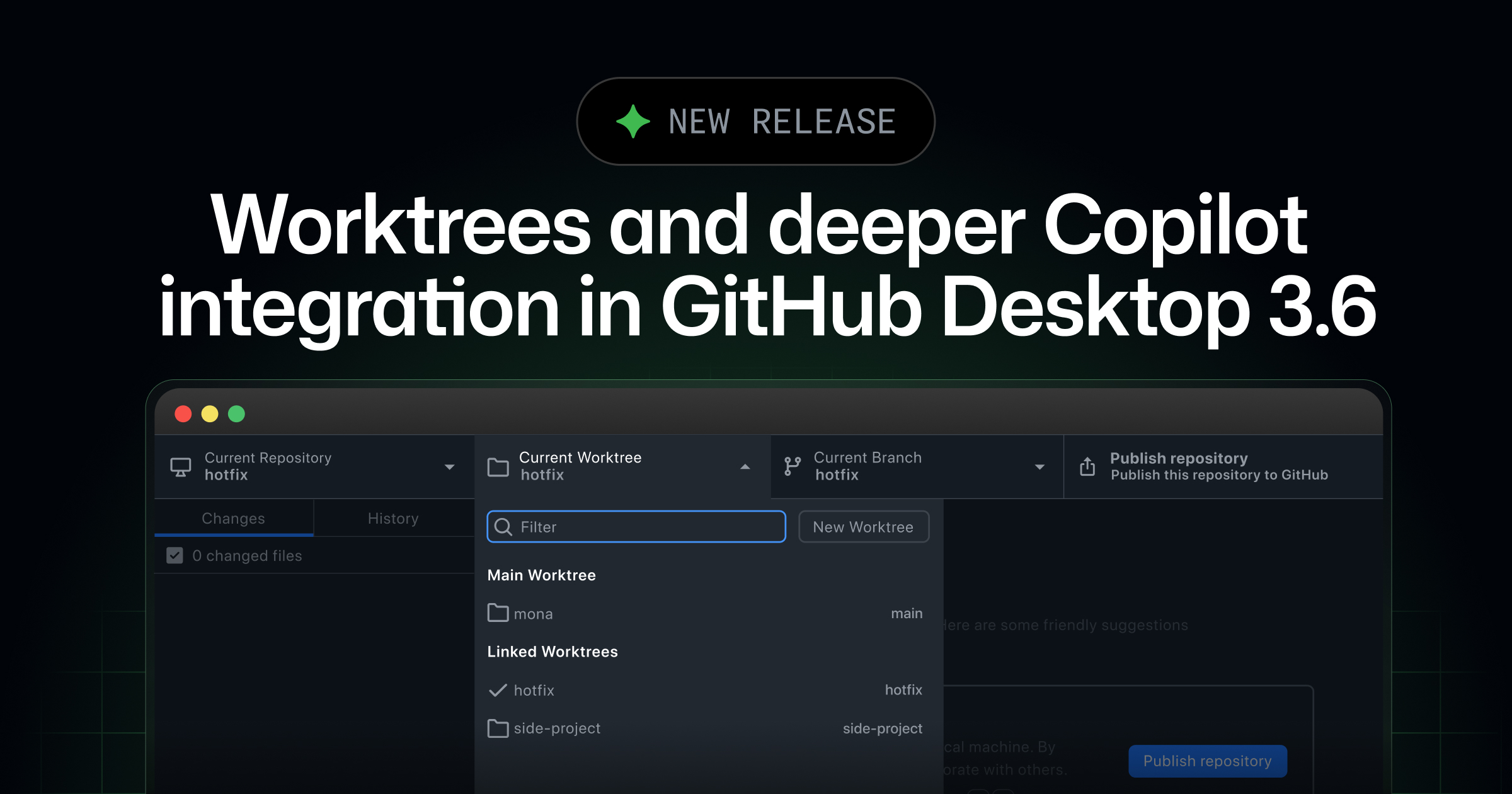
GitHub Desktop 3.6 Enhances Copilot Integration
GitHub Desktop 3.6 introduces significant enhancements with deeper integration of GitHub Copilot, making commit authoring and merge conflict resolution more intuitive. The update leverages the Copilot SDK, allowing users to select from various models and even connect third-party providers. This version also supports Git worktrees, enabling developers to manage multiple branches without the hassle of stashing changes or creating extra clones. These improvements streamline the Git workflow, making it more efficient and aligned with repository standards.
GitHub Changelog
More in Models & Labs
Models & Labsmodels
vLLM v0.24.0 Release Enhances Model Support
The vLLM v0.24.0 release marks a significant update with extensive contributions from 256 developers, introducing support for new models like MiniMax-M3 and DiffusionGemma. This version enhances performance with optimizations such as the FlashInfer sparse index cache and improved throughput for DeepSeek-V4. The update also expands the Model Runner V2 capabilities, supporting quantized models by default and integrating GraniteMoE. These advancements make vLLM more robust and versatile, offering developers improved tools for model deployment and performance tuning.
vLLM Releases
Models & Labsmodels
Llama.cpp b9833 Release Enhances MiniCPM5 Parser
The latest b9833 release of llama.cpp focuses on refining the MiniCPM5 parser, addressing several technical aspects to improve its functionality. This update includes the addition of a new tool call parser, refactoring of the PEG parser, and adjustments to the Jinja min/max API for better compatibility with Jinja2. The release also reverts some shared mapper changes to maintain strict JSON parsing for tool-call arguments. These enhancements aim to streamline the parsing process, ensuring more reliable and efficient handling of XML tool calls and grammar triggers.
llama.cpp Releases
Models & Labsmodels
llama.cpp b9835 Release Expands Platform Support
The latest b9835 release of llama.cpp continues its trend of broadening platform compatibility, though without major new features. Notably, the release includes support for ROCm 7.2 on Ubuntu x64, which is significant for AMD GPU users seeking alternatives to NVIDIA's CUDA. The update also maintains a wide array of builds across macOS, Linux, Windows, and openEuler, ensuring developers have the flexibility to deploy on diverse systems. While the release doesn't introduce groundbreaking changes, it solidifies llama.cpp's position as a versatile tool for AI inference across multiple environments.
llama.cpp Releases