Models & Labs
GitHub Enhances AI Adoption Metrics for Enterprises
GitHub Changeloghigh confidence
Why it matters
- →Provides a clearer picture of AI adoption's impact on development throughput.
- →Enables enterprises to analyze user behavior across different adoption phases.
- →Offers consistent metrics for better decision-making in AI-driven development.

GitHub has updated its Copilot usage metrics API to include total pull requests merged by AI adoption phase, enhancing the insights available to enterprise administrators and organization owners. Previously, the API only provided per-user averages, but now it offers a total count of pull requests merged daily by users in each adoption phase. This change allows for a clearer analysis of AI adoption's impact on development throughput and user behavior. The new metrics are available through the REST API, providing a consistent view alongside existing averages.
Read originalMore from GitHub Changelog
 © GitHub Changelog
© GitHub ChangelogModels & Labscoding
MAI-Code-1-Flash Now Available for GitHub Copilot
Microsoft AI's MAI-Code-1-Flash model is now generally available for GitHub Copilot Business and Enterprise users, marking a significant step in optimizing coding workflows. This model is designed to deliver fast, low-latency responses, making it ideal for high-volume, iterative coding tasks where speed is crucial. By integrating this model, GitHub aims to enhance the efficiency of Copilot users, particularly in enterprise environments. Administrators need to enable this feature in settings, highlighting a focus on customizable enterprise solutions.
GitHub Changelog
 © GitHub Changelog
© GitHub ChangelogCoding Toolscoding
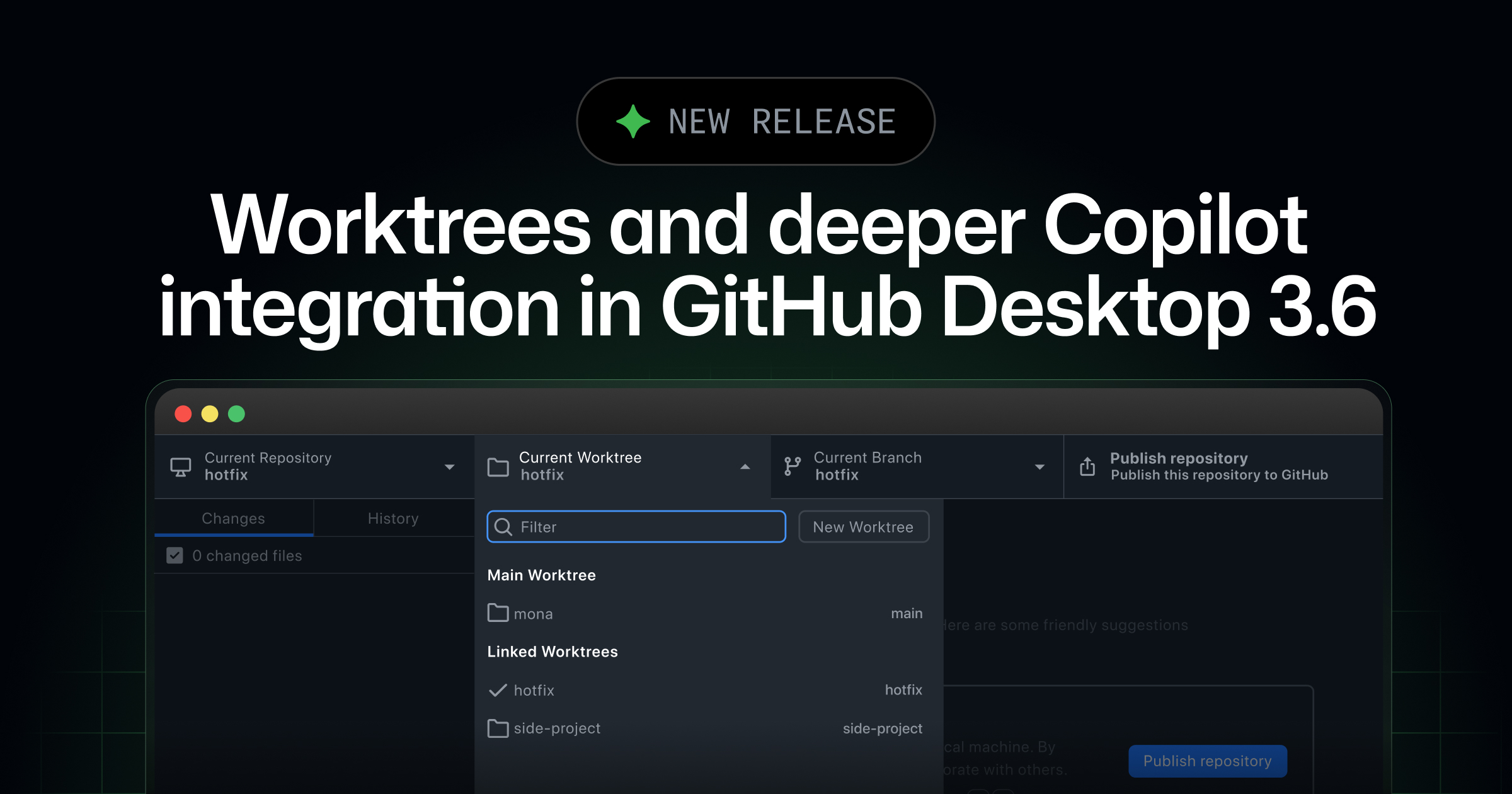
GitHub Desktop 3.6 Enhances Copilot Integration
GitHub Desktop 3.6 introduces significant enhancements with deeper integration of GitHub Copilot, making commit authoring and merge conflict resolution more intuitive. The update leverages the Copilot SDK, allowing users to select from various models and even connect third-party providers. This version also supports Git worktrees, enabling developers to manage multiple branches without the hassle of stashing changes or creating extra clones. These improvements streamline the Git workflow, making it more efficient and aligned with repository standards.
GitHub Changelog
 © GitHub Changelog
© GitHub ChangelogCoding Toolscoding
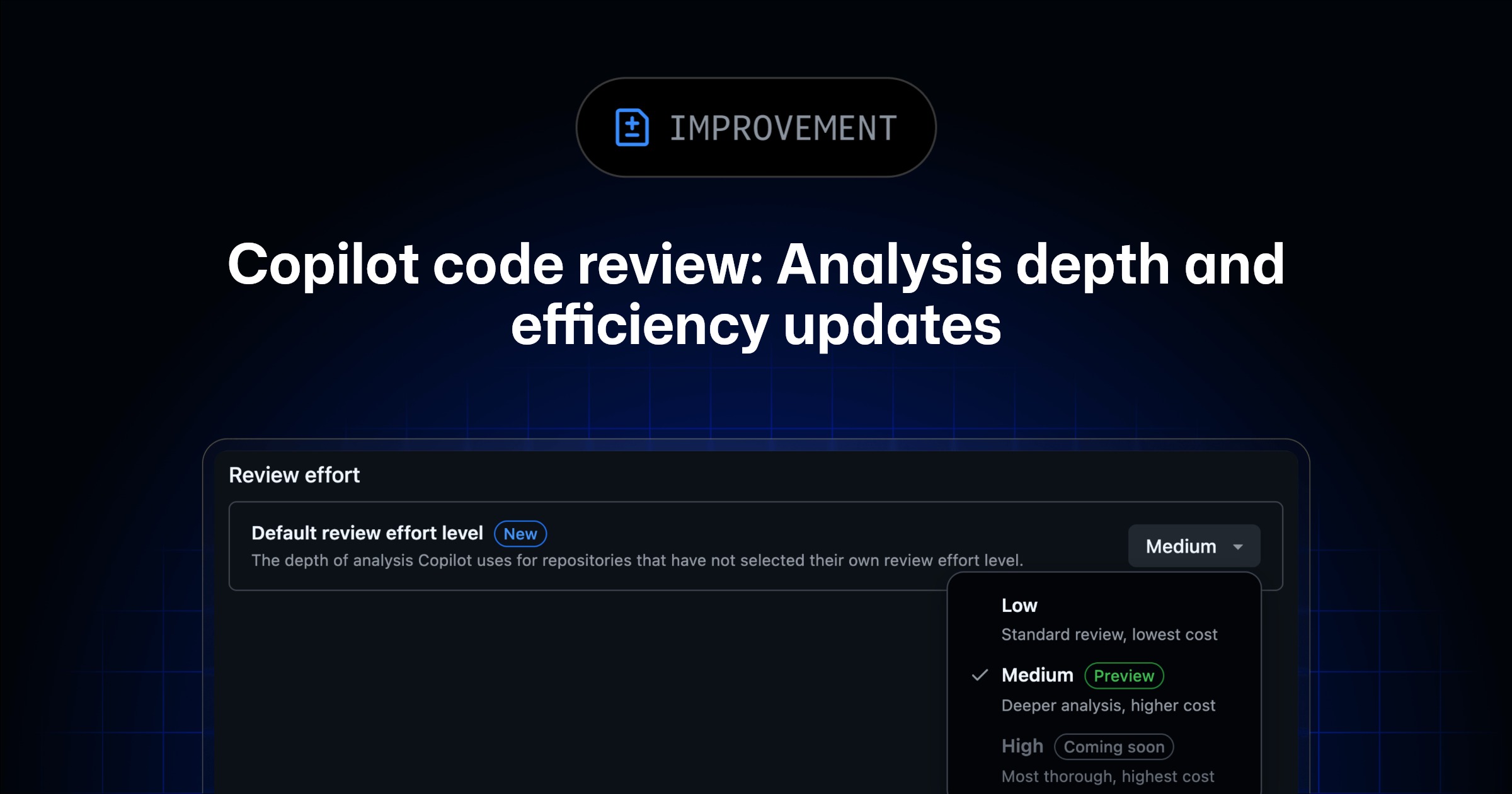
GitHub Copilot Enhances Code Review Efficiency
GitHub's Copilot code review has become more efficient with the integration of built-in file exploration tools from the Copilot CLI and SDK. This update reduces review costs by about 20% without altering existing workflows, thanks to the use of tools like grep and rg. Additionally, users in the Medium analysis depth public preview can now benefit from improved configurability and visibility of review depth. Organizations can set default review levels, enhancing control over the review process. These changes make Copilot's code review more focused and cost-effective.
GitHub Changelog
More in Models & Labs
Models & Labsmodels
llama.cpp b9817 release enhances OpenVINO support
The latest b9817 release of llama.cpp brings significant updates to its OpenVINO backend, including an upgrade to OV 2026.2.1 and the introduction of self-contained release packages. These changes streamline the deployment process and improve operator handling, making it easier for developers to integrate and utilize OpenVINO in their projects. Additionally, the update removes hardcoded compute operation types, enhancing flexibility and adaptability. This release marks a step forward in making llama.cpp a more versatile and developer-friendly platform, particularly for those leveraging OpenVINO's capabilities.
llama.cpp Releases
Models & Labsmodels
llama.cpp b9820 Release Enhances CUDA Performance
The b9820 release of llama.cpp brings notable improvements to CUDA performance by cutting down on unnecessary synchronizations, which can streamline token processing. This update introduces asynchronous copy capabilities between CPU and CUDA, facilitating smoother data transfers and potentially speeding up computations. Backend detection has been refined to avoid linking conflicts, and synchronization adjustments have been made more general, allowing other backends like Vulkan to benefit. These enhancements aim to optimize performance across different hardware setups, making llama.cpp a more adaptable tool for developers working with diverse configurations.
llama.cpp Releases
Models & Labsmodels
llama.cpp b9826 Release Expands Platform Support
The b9826 release of llama.cpp continues to enhance its reach by supporting a wider array of systems, though it doesn't bring new model architectures. With ROCm 7.2 now available for Ubuntu x64, AMD GPU users gain a viable alternative to NVIDIA's CUDA, broadening their options for AI inference. The update also includes builds for macOS, Linux, Windows, and openEuler, ensuring developers can utilize llama.cpp regardless of their operating environment. While the release doesn't introduce groundbreaking features, it reinforces llama.cpp's utility as a flexible tool for AI developers working across different hardware and software configurations.
llama.cpp Releases