Coding Tools
Run vLLM Server on HF Jobs with One Command
Hugging Face Bloghigh confidence
Why it matters
- →Simplifies the deployment of AI models for testing and evaluation.
- →Offers scalable solutions for handling larger models with ease.
- →Provides a cost-effective, temporary hosting option for developers.

Hugging Face has introduced a simplified method to deploy a vLLM server using their Jobs platform. By executing a single command, developers can quickly set up a model server for testing and evaluation purposes. The process involves using the vllm/vllm-openai image and selecting appropriate GPU resources, allowing for scalable deployments. This new capability is particularly useful for developers who need temporary model hosting without the complexity of managing infrastructure. The service is billed per minute, offering a cost-effective solution for short-term model usage.
Read originalMore from Hugging Face Blog
 © Hugging Face Blog
© Hugging Face BlogResearchresearch
Hybrid Models Show Strength in Predicting Meaningful Tokens
Hugging Face's recent study reveals that hybrid language models have distinct advantages over traditional transformers in predicting tokens that carry meaning, such as nouns and verbs. The Olmo Hybrid model outperforms transformers in these areas, showcasing its ability to handle complex language structures. However, when it comes to repetitive tokens, transformers maintain an edge due to their efficient attention mechanisms. This research highlights the importance of evaluating models based on specific token types to uncover architectural strengths. These insights are expected to guide the development of more refined hybrid models, potentially enhancing language model capabilities in the future.
Hugging Face Blog
 © Hugging Face Blog
© Hugging Face BlogModels & Labsmodels
NVIDIA NeMo AutoModel Boosts Transformers Fine-Tuning
NVIDIA's NeMo AutoModel is making waves by significantly accelerating the fine-tuning of Transformers, particularly for Mixture of Experts (MoE) models. By integrating Expert Parallelism and DeepEP fused dispatch, it achieves up to 3.7x higher training throughput and reduces GPU memory usage by up to 32% compared to native Transformers v5. This is achieved without altering the existing from_pretrained() API, making it accessible for developers already familiar with Hugging Face models. The innovation lies in its ability to scale efficiently across multiple GPUs, offering a seamless transition for those looking to optimize large-scale AI models.
Hugging Face Blog
 © Hugging Face Blog
© Hugging Face BlogResearchresearch
Hugging Face Launches FFASR Leaderboard for ASR Models
Hugging Face and Treble Technologies have unveiled the FFASR Leaderboard, a pioneering benchmark for assessing automatic speech recognition (ASR) models in realistic far-field acoustic settings. This initiative tackles the discrepancy between traditional benchmarks and actual performance, where elements like reverberation and ambient noise significantly affect model accuracy. By offering a community-driven platform, the leaderboard promotes the creation of models that can withstand these challenging conditions. This development is poised to redirect focus towards enhancing real-world acoustic robustness, providing a more precise evaluation of ASR model performance in complex acoustic scenarios.
Hugging Face Blog
More in Coding Tools
Coding Toolscoding
Claude Code v2.1.187 Release
The latest update to Claude Code, version 2.1.187, introduces several enhancements and fixes that improve usability and functionality. Notably, it adds a sandbox.credentials setting to prevent sandboxed commands from accessing sensitive files, and introduces model restrictions based on organizational settings. The update also addresses various bugs, such as fixing remote MCP tool calls that previously hung indefinitely and improving the handling of structured output. These changes make the platform more secure and efficient, enhancing the overall user experience.
Claude Code Releases
Coding Toolscoding
Claude Code v2.1.193 Update Released
Claude Code's latest update, v2.1.193, introduces several enhancements aimed at improving user experience and system efficiency. Notably, the update includes a new auto-mode classifier for Bash/PowerShell commands, providing more comprehensive command routing. Additionally, OpenTelemetry logging now captures assistant response text, offering deeper insights into model interactions. The update also addresses several bugs, such as issues with background tasks and agent prompts, ensuring smoother operation. These changes make Claude Code more robust and user-friendly, particularly for developers relying on its automation capabilities.
Claude Code Releases
 © GitHub Changelog
© GitHub ChangelogCoding Toolscoding
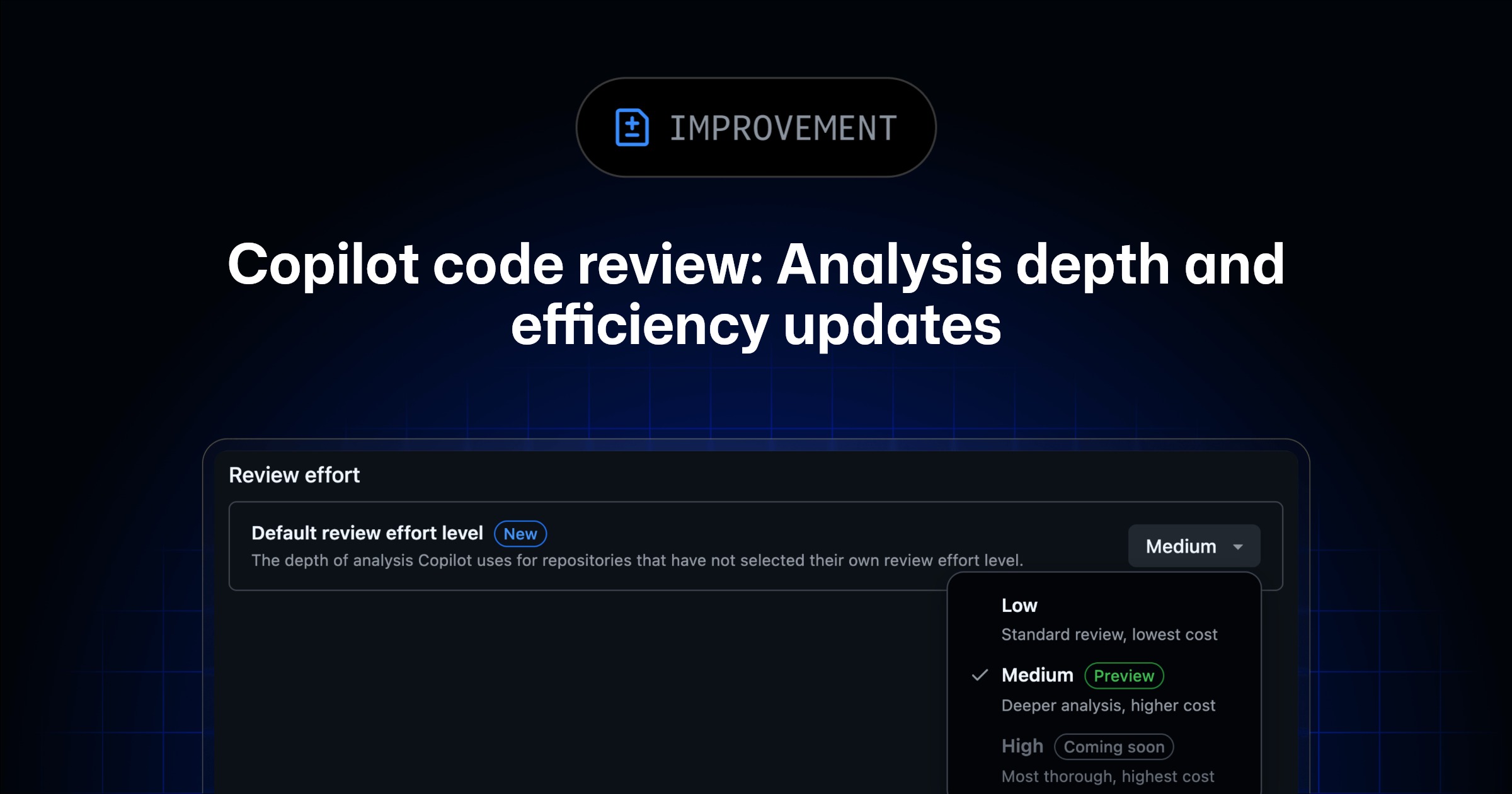
GitHub Copilot Enhances Code Review Efficiency
GitHub's Copilot code review has become more efficient with the integration of built-in file exploration tools from the Copilot CLI and SDK. This update reduces review costs by about 20% without altering existing workflows, thanks to the use of tools like grep and rg. Additionally, users in the Medium analysis depth public preview can now benefit from improved configurability and visibility of review depth. Organizations can set default review levels, enhancing control over the review process. These changes make Copilot's code review more focused and cost-effective.
GitHub Changelog