Models & Labs
VQ-Diffusion Simplifies Image Generation
Hugging Face Bloghigh confidence
Why it matters
- →VQ-Diffusion offers a new approach to image generation by using discrete diffusion processes.
- →It improves computational efficiency compared to traditional autoregressive models.
- →The method is accessible through Hugging Face's Diffusers library, enabling easy experimentation.
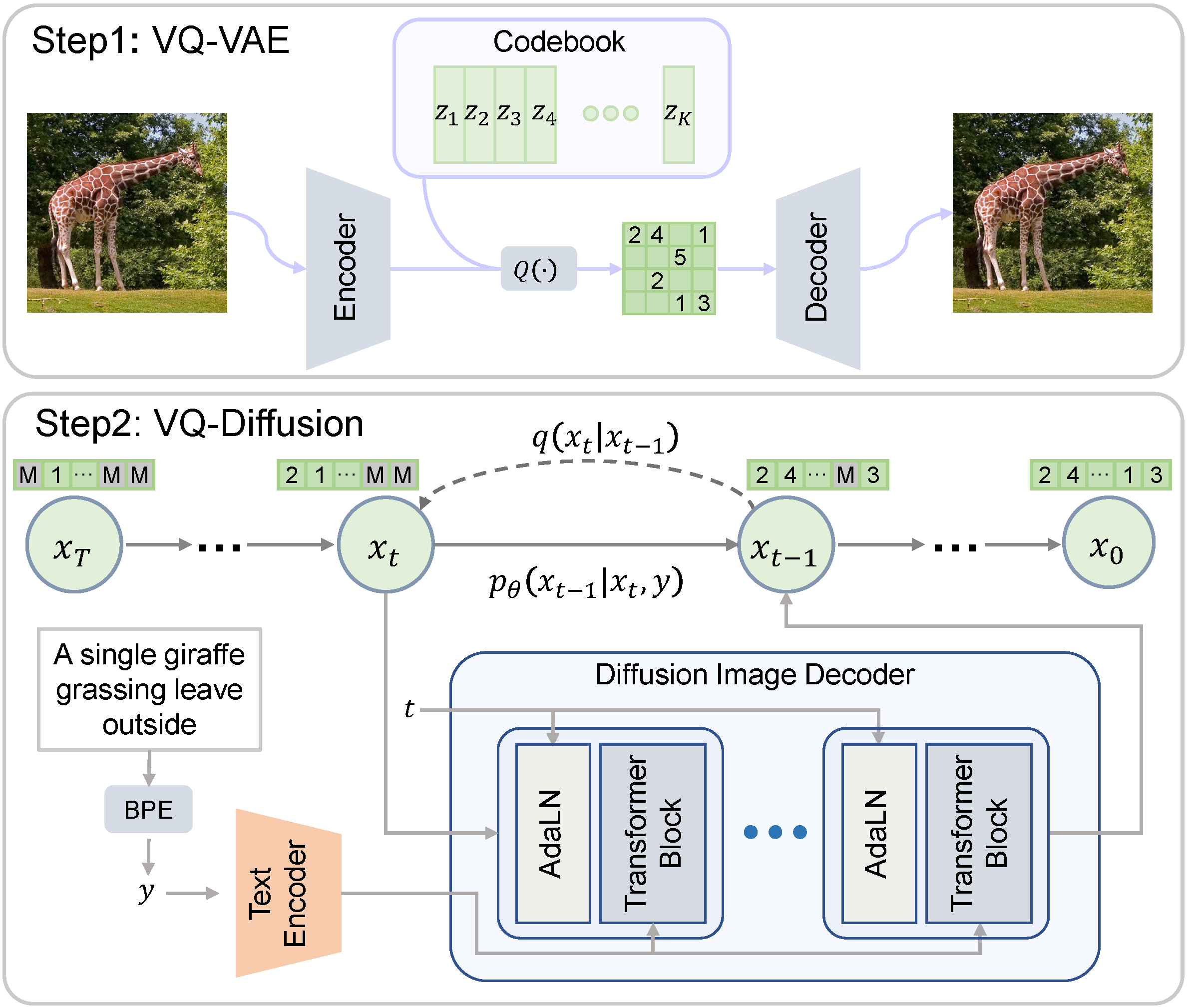
Hugging Face's Diffusers library now supports VQ-Diffusion, a novel approach to image generation using discrete diffusion processes. This method encodes images into discrete tokens via a VQ-VAE encoder, reducing dimensionality and improving computational efficiency. VQ-Diffusion addresses common issues in autoregressive models, such as inference speed and error accumulation. Developers can easily implement this model with a few lines of code, making it an accessible tool for exploring advanced image synthesis techniques.
Read originalMore from Hugging Face Blog
 © Hugging Face Blog
© Hugging Face BlogModels & Labsmodels
OlmoEarth Platform Enables Large-Scale Geospatial Inference
The OlmoEarth Platform is a significant advancement in geospatial inference, designed to handle the massive scale of Earth observation data. By processing terabytes of satellite imagery efficiently, it enables organizations to generate continent-scale maps in a day, at minimal cost. This platform addresses the challenges of data acquisition, processing, and inference, making it accessible even to organizations without extensive engineering resources. With its ability to run large-scale inference jobs using thousands of CPUs and GPUs, OlmoEarth is poised to transform how environmental data is utilized for applications like wildfire risk mapping and deforestation monitoring.
Hugging Face Blog
 © Hugging Face Blog
© Hugging Face BlogModels & Labsmodels
LFM2.5-Encoders Boost Long-Context Inference on CPU
Hugging Face's LFM2.5-Encoders represent a leap forward in handling long-context inference, particularly on CPU. These models outperform larger counterparts like ModernBERT-base in speed, efficiently managing up to 8,192-token contexts. This makes them particularly suitable for high-volume tasks such as classification and routing, where speed and cost-effectiveness are crucial. The models are open-source and available for immediate use, allowing developers to fine-tune them for specific applications. This release signals a move towards more efficient, CPU-friendly NLP solutions that maintain high performance without the need for extensive hardware.
Hugging Face Blog
 © Hugging Face Blog
© Hugging Face BlogModels & Labsmodels
NVIDIA Unveils Real-Time Surgical Simulator
NVIDIA's Cosmos-H-Dreams marks a significant leap in surgical robotics simulation by enabling real-time, action-conditioned generative environments. Building on the Cosmos-H-Surgical-Simulator, this new model operates on a single NVIDIA RTX PRO 6000 GPU, offering interactive simulations that can be controlled in a closed loop. By integrating with platforms like the Versius surgeon controller, Cosmos-H-Dreams demonstrates its versatility and potential for real-time operation. This development not only enhances the speed and efficiency of surgical simulations but also opens new possibilities for policy development and surgical training without the need for physical robots.
Hugging Face Blog
More in Models & Labs
Models & Labsmodels
Llama.cpp adds GLM-5.2 speculative decoding support
Llama.cpp's latest update introduces speculative decoding support for GLM-5.2, enhancing its capabilities with NextN/MTP features. This addition allows for more efficient tensor loading and context management, particularly benefiting models using the GLM_DSA architecture. The update also includes options for exporting models with or without the MTP feature, providing flexibility for developers. This release marks a step forward in optimizing model performance and adaptability, especially for those leveraging the GLM-5.2 framework.
llama.cpp Releases
Models & Labsmodels
Llama.cpp b10178 Release Adds Trace Logging
The b10178 release of llama.cpp enhances its server capabilities by adding trace logging for slot similarity checking, offering developers detailed insights into prompt cache slot selection processes. This update includes specifics on skip reasons and similarity calculations, which can aid in performance optimization. While no new model architectures are introduced, the release continues to support a wide array of platforms, such as macOS with KleidiAI, Ubuntu with ROCm 7.2, and Windows with CUDA 12 and 13. This makes llama.cpp a more versatile tool for developers working on different systems, reinforcing its position as a comprehensive inference runtime.
llama.cpp Releases
Models & Labsmodels
llama.cpp b10180 Release Enhances SYCL Performance
The b10180 release of llama.cpp brings notable improvements to SYCL performance, focusing on unary elementwise operations. By introducing a contiguous fast path and employing 32-bit index math, the update aims to boost computational efficiency. The integration of fastdiv for elementwise index math further enhances processing speed. Although there are no new models in this release, llama.cpp continues to evolve as a flexible inference runtime, now more efficient on systems like macOS, Linux, and Windows. Developers working with SYCL can expect smoother and faster operations, reinforcing llama.cpp's adaptability across different computing environments.
llama.cpp Releases